Questões de Concurso
Sobre algoritmos em algoritmos e estrutura de dados
Foram encontradas 1.889 questões
Analise o algoritmo abaixo, escrito no software VisuAlg 3.0.

Ao ser executado no VisuAlg 3.0, o algoritmo apresentará um aviso de problema. O que precisará ser
modificado para que o problema seja corrigido?
Abaixo está representada a declaração de uma variável em pseudocódigo (Portugol).
Notas: Vetor [1..10,1..3] de Real
Na declaração acima, quantas posições possui a variável Notas?

Analise o algoritmo abaixo, escrito no software VisuAlg 3.0:
algoritmo "concurso"
var
cont, res: inteiro
inicio
res <- 0;
para cont de 1 ate 8 faca
se (cont < 4) entao
res <- res + 1;
senao
res <- res - 1;
fimse
fimpara
fimalgoritmo
Ao final da execução do algoritmo acima, qual será o valor da variável “res”?
Analise o algoritmo abaixo, escrito no software VisuAlg 3.0:

Ao final da execução do algoritmo acima, qual variável conterá o maior valor numérico?

Nesse programa, o valor assumido ao seu final pela variável S é igual a:
O algoritmo Naive Bayes é amplamente utilizado em problemas de classificação, especialmente em aplicações de processamento de linguagem natural e análise de texto.
O princípio fundamental do algoritmo Naive Bayes
O Parallel Data Assimilation Framework (PDAF) é um pacote de software que simplifica a implementação de métodos de assimilação, provendo versões totalmente paralelizadas de algoritmos, como por exemplo, diferentes versões dos Filtros de Kalman por conjunto (EnKF). Um dos requisitos de funcionamento do PDAF é o uso de um protocolo padronizado de comunicação para computação paralela.
O principal padrão de comunicação entre os processos paralelos executados em um sistema de memória distribuída, é denominado
Utiliza-se uma rede neural recorrente para aprender o processo de assimilação, que por sua vez é treinada a partir dos estados de um sistema dinâmico e de seus resultados de assimilação correspondentes. Tais redes neurais recorrentes são implementadas com o uso de funções de ativação, que introduzem não linearidades às saídas dos neurônios das redes.
Assinale a opção que menos se adequa às características esperadas para funções de ativação.
Por exemplo: suponha que se busque um vetor x que resolva o sistema Hx = y, minimizando-se o funcional
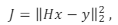
em que
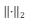 é a norma L2
(isto é, um problema de mínimos
quadrados mal-posto). Pode-se adicionar o termo de regularização
de Tikhonov ao funcional, substituindo-o por
é a norma L2
(isto é, um problema de mínimos
quadrados mal-posto). Pode-se adicionar o termo de regularização
de Tikhonov ao funcional, substituindo-o por 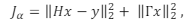
em que
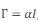 , e I é a matriz identidade.
, e I é a matriz identidade. Considere um caso hipotético onde as variáveis H, y e α possuem os seguintes valores:
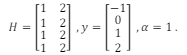
Neste caso, o vetor X que minimiza
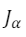 é:
é:1. Método de Newton
2. Broyden-Fletcher-Goldfarb-Shanno (BFGS)
3. Gradiente Conjugado
( ) Determina pontos cada vez mais próximos das soluções dos problemas de otimização mudando a direção de busca a cada iteração.
( ) Requer o cálculo das expressões fechadas dos gradientes e matrizes Hessianas a cada iteração.
( ) Utiliza aproximações de matrizes Hessianas e suas inversas para reduzir a carga computacional a cada iteração.
Assinale a opção que indica a relação correta, segundo a ordem apresentada.
Com relação à formulação variacional de assimilação de dados, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Trata-se da busca por estados dos sistemas que minimizam um funcional de custo, em geral definido como um erro quadrático entre observações e predições correspondentes àqueles estados, calculadas por modelos matemáticos.
( ) Envolve a necessidade de aplicação de técnicas de localização e/ou inflação de covariâncias para eliminar correlações espurias entre possíveis soluções de problemas de otimização.
( ) Baseia-se em otimizações com restrições dinâmicas fortes, introduzidas no problema por uso de multiplicadores de Largrange; ou fracas, introduzidas no problema como termos ponderados de penalidades.
As afirmativas são, respectivamente,
Essa alta dimensionalidade impõe grandes dificuldades para a aplicação de filtros de partículas (PF) em problemas de assimilação de dados com muitas observações independentes, porque nessas situações o número de partículas necessárias para representar as distribuições de probabilidade cresce exponencialmente.
Técnicas recentemente desenvolvidas que visam contornar essas dificuldades baseiam-se em combinar filtros de partículas e filtros de Kalman por conjunto (EnKF), criando-se soluções híbridas PF-EnKF.
Assinale a opção que indica a principal vantagem de se utilizar filtros híbridos PF-EnKF.
Uma forma de produzir um novo conjunto de partículas em pontos distintos é substituir as distribuições discretas de probabilidade por aproximações contínuas e, somente então, realizar a reamostragem. A criação dessas aproximações se dá por meio de uma operação matemática entre a distribuição de probabilidade discreta e um kernel contínuo.
Nesse contexto, o processo de reamostragem em distribuições de probabilidade contínuas, que aproximam distribuições discretas correspondentes às configurações de partículas, é chamado de
Considerando um filtro de partículas com N partículas cujos pesos são dados por w(i) ,i = 1, … , N, a estimativa do número efetivo de partículas é dada por