Questões de Concurso
Sobre algoritmos em algoritmos e estrutura de dados
Foram encontradas 1.889 questões
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457921
Algoritmos e Estrutura de Dados
Considere a sentença a seguir.
s: “O acesso ao auditório também pode ser feito através de uma rampa”
Aplicando a função f à sentença, obtém-se o seguinte resultado:
f(s) = “acesso auditório pode ser feito através rampa”
A tarefa de tratamento de dados textuais realizada pela função f é:
s: “O acesso ao auditório também pode ser feito através de uma rampa”
Aplicando a função f à sentença, obtém-se o seguinte resultado:
f(s) = “acesso auditório pode ser feito através rampa”
A tarefa de tratamento de dados textuais realizada pela função f é:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457920
Algoritmos e Estrutura de Dados
PV-DM (do inglês, Paragraph Vector Distributed Memory) é
um método de aprendizado de máquina utilizado no
processamento de dados textuais. A ideia central é prever
uma palavra (de contexto) a partir de um conjunto de
palavras amostrado aleatoriamente – palavras de contexto
e ID de parágrafo. Quando aplicado sobre um conjunto de
documentos textuais (por exemplo, os processos deferidos
arquivados no TJ-AC), qual a vantagem desse método em
relação ao método BOW, baseado em contagem de
palavras?
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457919
Algoritmos e Estrutura de Dados
Para reduzir a dimensionalidade de um conjunto de dados
bidimensionais, foi executado o algoritmo PCA (do inglês,
Principal Component Analysis). Se o PCA produzir como
resultado dois autovalores de mesmo valor, significa que
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457917
Algoritmos e Estrutura de Dados
O pré-processamento é um conjunto de atividades que
envolvem preparação, organização e estruturação de
dados, sendo fundamental no desempenho do modelo de
aprendizagem de máquina. Tais atividades contemplam
métodos e técnicas de limpeza, transformação, integração
e redução de dimensionalidade. Os métodos que podem
ser utilizados para o tratamento de dados faltantes são:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457916
Algoritmos e Estrutura de Dados
Random Forest são algoritmos de aprendizado de máquina
utilizados para classificação ou regressão, sendo vantajoso
em relação às árvores de decisão no caso de
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457915
Algoritmos e Estrutura de Dados
A camada de uma rede convolucional que tem como
função primária reduzir progressivamente o tamanho
espacial do volume de dados de entrada por meio do
mapeamento de seções de features e diminuição dos
pesos de treinamento é denominada camada de
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457914
Algoritmos e Estrutura de Dados
Uma rede neural foi implementada a partir da arquitetura
Multilayer Perceptron (MLP) e o conjunto de dados foi
dividido em holdout com 50% para conjunto de
treinamento, 30% para conjunto de validação e 20% para
conjunto de teste. Se, durante o treinamento e a validação
da referida rede ocorreu underfitting, dois fatores que
podem ter condicionado tal fenômeno são:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457913
Algoritmos e Estrutura de Dados
Uma das métricas mais comumente utilizadas para
comparar resultados de algoritmos de clusterização é
obtida por meio da fórmula (b-a)/ max(a,b), em que:
a é a distância média entre os pontos dentro de cada cluster (distância média intra-cluster) e
b é a distância média para o cluster mais próximo (distância média para os pontos do cluster mais próximo).
A métrica descrita recebe o nome de:
a é a distância média entre os pontos dentro de cada cluster (distância média intra-cluster) e
b é a distância média para o cluster mais próximo (distância média para os pontos do cluster mais próximo).
A métrica descrita recebe o nome de:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457912
Algoritmos e Estrutura de Dados
Seja a matriz de confusão obtida na avaliação de
desempenho de um modelo de aprendizado treinado para
classificar processos julgados pelo TJ-AC:

Os valores da performance geral, da sensibilidade e da precisão do modelo são, respectivamente:
Os valores da performance geral, da sensibilidade e da precisão do modelo são, respectivamente:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457911
Algoritmos e Estrutura de Dados
Observe o gráfico a seguir.
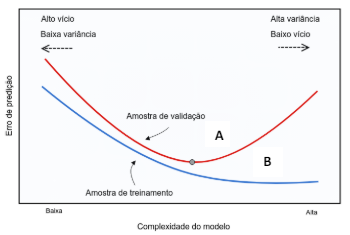
Disponível em: <http://cursos.leg.ufpr.br/ML4all/apoio/reamostragem.html>. Acesso em: mar. 2024.
O gráfico representa as regiões de overfitting e underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina com o erro de predição. A partir do exposto no gráfico, o erro de generalização do modelo ocorre na região:
Disponível em: <http://cursos.leg.ufpr.br/ML4all/apoio/reamostragem.html>. Acesso em: mar. 2024.
O gráfico representa as regiões de overfitting e underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina com o erro de predição. A partir do exposto no gráfico, o erro de generalização do modelo ocorre na região:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457910
Algoritmos e Estrutura de Dados
Para classificar os processos tramitados no TJ-AC em
duas categorias (deferidos e indeferidos), um analista
escolheu um algoritmo que divide os dados de entrada em
duas regiões separadas por uma linha e resulta em uma
simetria na classificação, de forma que o ponto mais
próximo de cada classe está a uma distância d do ponto
médio entre os dois grupos de classe (hiperplano). O
algoritmo descrito é denominado:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457909
Algoritmos e Estrutura de Dados
O ecossistema Hadoop se refere aos vários componentes
da biblioteca de software Apache Hadoop, incluindo
projetos de código aberto e ferramentas complementares
para armazenar e processar Big Data. Algumas das
ferramentas mais conhecidas incluem HDFS, Pig, YARN,
MapReduce, Spark, HBase Oozie, Sqoop e Kafka, cada
uma com função específica no ecossistema Hadoop. São
funções dos componentes do ecossistema Hadoop:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457907
Algoritmos e Estrutura de Dados
O aprendizado de máquina (do inglês, machine learning) é
um conjunto de técnicas da ciência de dados que permite
que os computadores usem os dados existentes para
prever comportamentos, resultados e tendências. Uma das
formas de classificar o aprendizado é em razão da
natureza do sinal de entrada ou feedback do processo. As
árvores de decisão, agrupamento e regras de associação
são, respectivamente, técnicas de aprendizado de
máquina:
Ano: 2024
Banca:
FUNDEP (Gestão de Concursos)
Órgão:
UFOP
Prova:
FUNDEP (Gestão de Concursos) - 2024 - UFOP - Analista de Tecnologia da Informação |
Q2453278
Algoritmos e Estrutura de Dados
Analise o método de ordenação representado pelo algoritmo
a seguir.
• Dividir recursivamente o vetor a ser ordenado em dois, até obter n vetores de 1 único elemento.
• Aplicar a intercalação tendo como entrada 2 vetores de um elemento, formando um vetor ordenado de dois elementos.
• Repetir esse processo formando vetores ordenados cada vez maiores, até que todo o vetor esteja ordenado.
Qual é o método de ordenação representado pelo algoritmo?
• Dividir recursivamente o vetor a ser ordenado em dois, até obter n vetores de 1 único elemento.
• Aplicar a intercalação tendo como entrada 2 vetores de um elemento, formando um vetor ordenado de dois elementos.
• Repetir esse processo formando vetores ordenados cada vez maiores, até que todo o vetor esteja ordenado.
Qual é o método de ordenação representado pelo algoritmo?
Ano: 2024
Banca:
FUNDEP (Gestão de Concursos)
Órgão:
UFOP
Prova:
FUNDEP (Gestão de Concursos) - 2024 - UFOP - Analista de Tecnologia da Informação |
Q2453272
Algoritmos e Estrutura de Dados
Analise o algoritmo a seguir.
• Passo 1. Encontre o menor item do vetor
• Passo 2. Troque-o de lugar com o item da primeira posição do vetor.
• Passo 3. Repita essas duas operações com os n − 1 itens restantes, depois com os n − 2 itens, até que reste apenas um elemento.
Qual é o método de ordenação descrito pelo algoritmo?
• Passo 1. Encontre o menor item do vetor
• Passo 2. Troque-o de lugar com o item da primeira posição do vetor.
• Passo 3. Repita essas duas operações com os n − 1 itens restantes, depois com os n − 2 itens, até que reste apenas um elemento.
Qual é o método de ordenação descrito pelo algoritmo?
Q2452844
Algoritmos e Estrutura de Dados
Analise o algoritmo abaixo, escrito no software VisuAlg 3.0:

Ao final da execução do algoritmo acima, qual será o valor da variável “final”?
Ano: 2024
Banca:
FUNDATEC
Órgão:
CREMERS
Prova:
FUNDATEC - 2024 - CREMERS - Técnico de Informática |
Q2452267
Algoritmos e Estrutura de Dados
Analise o algoritmo abaixo, escrito no software VisuAlg 3.0:

O que será impresso a partir da execução do algoritmo?
Ano: 2024
Banca:
FUNDATEC
Órgão:
CREMERS
Prova:
FUNDATEC - 2024 - CREMERS - Técnico de Informática |
Q2452266
Algoritmos e Estrutura de Dados
Em pseudocódigo (Portugol), qual das estruturas abaixo corresponde a um tipo de
estrutura condicional composta?
Ano: 2024
Banca:
FUNDATEC
Órgão:
CREMERS
Prova:
FUNDATEC - 2024 - CREMERS - Técnico de Informática |
Q2452265
Algoritmos e Estrutura de Dados
No contexto de programação de algoritmos, uma função que chama a si mesma é
conhecida como função:
Ano: 2024
Banca:
FGV
Órgão:
TJ-AP
Prova:
FGV - 2024 - TJ-AP - Apoio Especializado - Tecnologia da Informação - Desenvolvimento de Sistemas |
Q2447907
Algoritmos e Estrutura de Dados
Considere as variáveis A, B e C contendo os seguintes números
com as suas respectivas bases.
A = 1616
B = 1010
C = 102
O cálculo da soma de A + B + C é:
A = 1616
B = 1010
C = 102
O cálculo da soma de A + B + C é: