Questões de Concurso
Sobre algoritmos em algoritmos e estrutura de dados
Foram encontradas 1.889 questões
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518298
Algoritmos e Estrutura de Dados
Filtros de Partículas são implementações não paramétricas de filtros
Bayesianos em que as distribuições de probabilidade não são
explicitamente definidas, sendo, portanto, representadas por um
conjunto de amostras provenientes delas próprias (denominadas
partículas).
Com relação aos filtros de partículas, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) As partículas representam observações (ou medidas) obtidas por sensores aplicados ao sistema em análise, e a elas são associados pesos proporcionais às suas probabilidades de coincidirem com medidas correspondentes ao estado verdadeiro do sistema.
( ) Quando aplicados à assimilação de dados, a cada passo de assimilação, novos pesos são atribuídos às partículas. Caso não seja realizado nenhum processo de reamostragem, o conjunto de partículas costuma degenerar-se, com uma das partículas recebendo peso normalizado próximo de 1 e as outras partículas recebendo pesos normalizados próximos de 0.
( ) São capazes de representar distribuições de probabilidade multimodais, isto é, cujas densidades de probabilidade possuem mais de um máximo local.
As afirmativas são, respectivamente,
Com relação aos filtros de partículas, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) As partículas representam observações (ou medidas) obtidas por sensores aplicados ao sistema em análise, e a elas são associados pesos proporcionais às suas probabilidades de coincidirem com medidas correspondentes ao estado verdadeiro do sistema.
( ) Quando aplicados à assimilação de dados, a cada passo de assimilação, novos pesos são atribuídos às partículas. Caso não seja realizado nenhum processo de reamostragem, o conjunto de partículas costuma degenerar-se, com uma das partículas recebendo peso normalizado próximo de 1 e as outras partículas recebendo pesos normalizados próximos de 0.
( ) São capazes de representar distribuições de probabilidade multimodais, isto é, cujas densidades de probabilidade possuem mais de um máximo local.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518297
Algoritmos e Estrutura de Dados
Considere o modelo não linear e o Filtro de Kalman por Conjunto
(EnKF) detalhados na questão 04.
Para garantir estimativas de covariâncias não enviesadas, a matriz B pode ser calculada pela expressão:
Para garantir estimativas de covariâncias não enviesadas, a matriz B pode ser calculada pela expressão:
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518296
Algoritmos e Estrutura de Dados
Seja um modelo não linear dado por:
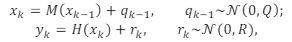
em que: xk é um vetor de estados de n dimensões em um dado instante de tempo K; M e H são mapeamentos não-lineares de Rn para Rn e de Rm para Rm, respectivamente; q e r são vetores aleatórios gaussianos de média nula e covariância Q e R, respectivamente.
Considere a implementação de um Filtro de Kalman por Conjunto (Ensemble Kalman Filter - EnKF) com 1000 pontos representando possíveis estados. Cada um dos 1000 pontos é denotado xt(i), onde i é inteiro e varia de 1 a 1000.
Considere, ainda, que a média dos pontos do conjunto no instante k pode ser representada por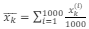 , e que o ganho de
Kalman no instante k é geralmente representado pelo produto de
uma matriz A pela inversa de uma matriz B (Kk = AB−1).
, e que o ganho de
Kalman no instante k é geralmente representado pelo produto de
uma matriz A pela inversa de uma matriz B (Kk = AB−1).
Considerando as condições enunciadas acima, para garantir estimativas de covariâncias não enviesadas, a matriz A pode ser calculada pela expressão:
em que: xk é um vetor de estados de n dimensões em um dado instante de tempo K; M e H são mapeamentos não-lineares de Rn para Rn e de Rm para Rm, respectivamente; q e r são vetores aleatórios gaussianos de média nula e covariância Q e R, respectivamente.
Considere a implementação de um Filtro de Kalman por Conjunto (Ensemble Kalman Filter - EnKF) com 1000 pontos representando possíveis estados. Cada um dos 1000 pontos é denotado xt(i), onde i é inteiro e varia de 1 a 1000.
Considere, ainda, que a média dos pontos do conjunto no instante k pode ser representada por
, e que o ganho de
Kalman no instante k é geralmente representado pelo produto de
uma matriz A pela inversa de uma matriz B (Kk = AB−1). Considerando as condições enunciadas acima, para garantir estimativas de covariâncias não enviesadas, a matriz A pode ser calculada pela expressão:
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518294
Algoritmos e Estrutura de Dados
A utilização de Filtros de Kalman clássicos (Kalman Filters - KF) ou
estendidos (Extended Kalman Filters - EKF) para a assimilação de
dados envolve dificuldades práticas.
Com relação a essas dificuldades, analise as afirmativas a seguir.
I. O EKF é o método otimizado para a assimilação de dados sequencial de um modelo dinâmico linear n-dimensional, sendo o KF apropriado apenas para sistemas unidimensionais.
II. O uso do KF e do EKF em modelos dinâmicos que contam com vetores de estados com muitas dimensões requer alta capacidade computacional e de armazenamento, tornando-os práticos apenas para modelos simplificados, de baixa dimensionalidade.
III. A linearização de modelos não lineares envolve a aproximação de funções matemáticas com o truncamento de séries, o que pode gerar erros de propagação de covariâncias, especialmente em modelos de alta dimensionalidade.
Está correto o que se afirma em
Com relação a essas dificuldades, analise as afirmativas a seguir.
I. O EKF é o método otimizado para a assimilação de dados sequencial de um modelo dinâmico linear n-dimensional, sendo o KF apropriado apenas para sistemas unidimensionais.
II. O uso do KF e do EKF em modelos dinâmicos que contam com vetores de estados com muitas dimensões requer alta capacidade computacional e de armazenamento, tornando-os práticos apenas para modelos simplificados, de baixa dimensionalidade.
III. A linearização de modelos não lineares envolve a aproximação de funções matemáticas com o truncamento de séries, o que pode gerar erros de propagação de covariâncias, especialmente em modelos de alta dimensionalidade.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518293
Algoritmos e Estrutura de Dados
Filtros Bayesianos são métodos usados para estimar o estado de um
sistema dinâmico que seja observado por meio de medidas com
incertezas. Entre os algoritmos utilizados para implementação de
filtros Bayesianos, pode-se citar o Filtro de Kalman clássico, aplicável
a sistemas de modelos lineares e com distribuições Gaussianas de
probabilidade.
Nesse contexto, assinale a opção que indica uma das características do Filtro de Kalman clássico.
Nesse contexto, assinale a opção que indica uma das características do Filtro de Kalman clássico.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518292
Algoritmos e Estrutura de Dados
Texto associado
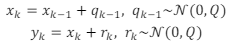
Seja um modelo dinâmico discreto unidimensional de caminhada
aleatória dado por:
Em que xk e yk são, respectivamente, o estado a ser estimado e a
medição no tempo k. As variáveis aleatórias qk e rk possuem
distribuição normal com média nula e variâncias Q e R,
respectivamente, ambas iguais a 1. Assuma, ainda, que a distribuição
de probabilidade do estado no tempo k independe da distribuição
de probabilidade dos estados anteriores (i.e., o sistema atende à
propriedade de Markov).
Em um determinado instante de tempo k − 1, o estado estimado
por um filtro de Kalman é dado por 2,5 e sua variância é estimada
em 1,0.
No instante de tempo k, obtém-se uma medição igual a 3,1.
Após se agregar a informação proveniente da medição no tempo k,
o valor estimado da variância do estado para esse mesmo instante k
será
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518291
Algoritmos e Estrutura de Dados
Texto associado
Seja um modelo dinâmico discreto unidimensional de caminhada
aleatória dado por:
Em que xk e yk são, respectivamente, o estado a ser estimado e a
medição no tempo k. As variáveis aleatórias qk e rk possuem
distribuição normal com média nula e variâncias Q e R,
respectivamente, ambas iguais a 1. Assuma, ainda, que a distribuição
de probabilidade do estado no tempo k independe da distribuição
de probabilidade dos estados anteriores (i.e., o sistema atende à
propriedade de Markov).
Em um determinado instante de tempo k − 1, o estado estimado
por um filtro de Kalman é dado por 2,5 e sua variância é estimada
em 1,0.
No instante de tempo k, obtém-se uma medição igual a 3,1.
Após agregar a informação proveniente da medição no tempo k, o
valor estimado do estado para esse mesmo instante k será
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518290
Algoritmos e Estrutura de Dados
Texto associado
Seja um modelo dinâmico discreto unidimensional de caminhada
aleatória dado por:
Em que xk e yk são, respectivamente, o estado a ser estimado e a
medição no tempo k. As variáveis aleatórias qk e rk possuem
distribuição normal com média nula e variâncias Q e R,
respectivamente, ambas iguais a 1. Assuma, ainda, que a distribuição
de probabilidade do estado no tempo k independe da distribuição
de probabilidade dos estados anteriores (i.e., o sistema atende à
propriedade de Markov).
Em um determinado instante de tempo k − 1, o estado estimado
por um filtro de Kalman é dado por 2,5 e sua variância é estimada
em 1,0.
No instante de tempo k, obtém-se uma medição igual a 3,1.
Antes de agregar a informação proveniente da medição no tempo k,
a predição da variância do estado, para esse mesmo instante k, será
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518289
Algoritmos e Estrutura de Dados
Texto associado
Seja um modelo dinâmico discreto unidimensional de caminhada
aleatória dado por:
Em que xk e yk são, respectivamente, o estado a ser estimado e a
medição no tempo k. As variáveis aleatórias qk e rk possuem
distribuição normal com média nula e variâncias Q e R,
respectivamente, ambas iguais a 1. Assuma, ainda, que a distribuição
de probabilidade do estado no tempo k independe da distribuição
de probabilidade dos estados anteriores (i.e., o sistema atende à
propriedade de Markov).
Em um determinado instante de tempo k − 1, o estado estimado
por um filtro de Kalman é dado por 2,5 e sua variância é estimada
em 1,0.
No instante de tempo k, obtém-se uma medição igual a 3,1.
Nessas condições, antes de se agregar a informação proveniente da
medição no instante de tempo k, a predição do estado para esse
mesmo instante k será
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518288
Algoritmos e Estrutura de Dados
Os Filtros Bayesianos são assim chamados por basearem-se na
aplicação do Teorema de Bayes, que relaciona distribuições de
probabilidade a priori com distribuições de probabilidade a
posteriori.
Há dois passos fundamentais para a estimação de estados, onde o primeiro passo está associado ao modelo dinâmico do sistema ou processo, enquanto o segundo passo está associado ao modelo de observações ou sensoriamento.
Neste contexto, os passos são denominados, respectivamente,
Há dois passos fundamentais para a estimação de estados, onde o primeiro passo está associado ao modelo dinâmico do sistema ou processo, enquanto o segundo passo está associado ao modelo de observações ou sensoriamento.
Neste contexto, os passos são denominados, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518285
Algoritmos e Estrutura de Dados
Algoritmos de estimação aplicados a assimilação de dados requerem
a solução de um problema de otimização.
Assinale a opção que indica o método que pode ser considerado híbrido.
Assinale a opção que indica o método que pode ser considerado híbrido.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518283
Algoritmos e Estrutura de Dados
Uma pesquisa sobre a dispersão espacial do risco de ocorrência de
um determinado fenômeno utilizou a estimação Bayesiana como
método de estimação.
Sobre esse método de estimação, assinale a opção correta.
Sobre esse método de estimação, assinale a opção correta.
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518081
Algoritmos e Estrutura de Dados
Pedro adotou o algoritmo apresentado a seguir para ordenar um
vetor de inteiros V, com índices variando de 1 até n.
Para K de 2 até n faça:
X <- V[K]
W <- (K – 1)
Enquanto W > 0 e V[W] > X faça:
V[W+1] <- V[W]
W <- (W-1)
Fim Enquanto
V[W+1] <- X
Fim Para
O algoritmo utilizado por Pedro foi o:
Para K de 2 até n faça:
X <- V[K]
W <- (K – 1)
Enquanto W > 0 e V[W] > X faça:
V[W+1] <- V[W]
W <- (W-1)
Fim Enquanto
V[W+1] <- X
Fim Para
O algoritmo utilizado por Pedro foi o:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518080
Algoritmos e Estrutura de Dados
O cálculo da complexidade computacional é essencial para
verificar a viabilidade do algoritmo. Observe o código a seguir,
em Python, para o problema da torre de Hanoi.
def hanoi(n, o, d, a):
if n==1:
print("D1 de "+o+" p/ "+d)
else:
hanoi(n-1, o, a, d)
print("D"+str(n)+" de "+o+" p/ "+d)
hanoi(n-1, a, d, o)
A complexidade desse algoritmo no pior caso é:
def hanoi(n, o, d, a):
if n==1:
print("D1 de "+o+" p/ "+d)
else:
hanoi(n-1, o, a, d)
print("D"+str(n)+" de "+o+" p/ "+d)
hanoi(n-1, a, d, o)
A complexidade desse algoritmo no pior caso é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518079
Algoritmos e Estrutura de Dados
Diversas operações matemáticas podem ser implementadas de
forma recursiva, como no algoritmo seguinte.
Função X (J: inteiro, K: inteiro)
Início
Se J < K Então
Retorne J
Senão
Retorne X (J-K, K)
Fim
Considerando o domínio dos inteiros positivos, a função terá como resultado o(a):
Função X (J: inteiro, K: inteiro)
Início
Se J < K Então
Retorne J
Senão
Retorne X (J-K, K)
Fim
Considerando o domínio dos inteiros positivos, a função terá como resultado o(a):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518068
Algoritmos e Estrutura de Dados
O analista José precisa escolher entre dois algoritmos, Abusca e
Cbusca. José sabe que, sendo N o tamanho da entrada do
algoritmo, Abusca requer 2N + log2(N) operações para ser
executado. Já o Cbusca requer N4 + N operações para ser
executado. José determinou, na notação O-grande, a
complexidade de tempo no pior caso para cada algoritmo e, por
fim, deve escolher o algoritmo que apresenta a menor ordem de
complexidade no pior caso.
José deve escolher o algoritmo:
José deve escolher o algoritmo:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518064
Algoritmos e Estrutura de Dados
O analista Joaquim precisou ordenar um array com N elementos.
Para economizar tempo, Joaquim optou por usar um algoritmo já
disponível na biblioteca de ordenação. A biblioteca contém as
implementações originais dos algoritmos Quicksort, Selection
Sort, Insertion Sort, Merge Sort e Heap Sort. O analista escolheu
o algoritmo que, no pior caso, apresenta uma relação quadrática
entre a quantidade de operações necessárias para a ordenação e
o número de elementos do array. No caso médio, a quantidade
de operações necessárias se aproxima de N multiplicado por um
logaritmo de N.
Joaquim escolheu o algoritmo de ordenação:
Joaquim escolheu o algoritmo de ordenação:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517633
Algoritmos e Estrutura de Dados
Uma certa organização busca melhorar a qualidade e agilidade do
seu atendimento eletrônico. Para isso um projeto foi criado para
agrupar os e-mails recebidos de acordo com o tipo de problema a
ser resolvido e assim repassá-los para o setor mais apropriado.
A equipe responsável pela implementação do projeto resolveu utilizar um modelo de linguagem recente para representar o máximo possível de informação contida num e-mail em um vetor de dimensão 768. Entretanto, depararam-se com o seguinte problema: as distâncias entre os vetores se mostraram muito pequenas, tornando o agrupamento por diversos algoritmos muito pouco significativo.
Com esse último problema em mente, a sequência mais apropriada de algoritmos a ser aplicada sobre os vetores, de forma a obter um agrupamento significativo dos e-mails, é:
A equipe responsável pela implementação do projeto resolveu utilizar um modelo de linguagem recente para representar o máximo possível de informação contida num e-mail em um vetor de dimensão 768. Entretanto, depararam-se com o seguinte problema: as distâncias entre os vetores se mostraram muito pequenas, tornando o agrupamento por diversos algoritmos muito pouco significativo.
Com esse último problema em mente, a sequência mais apropriada de algoritmos a ser aplicada sobre os vetores, de forma a obter um agrupamento significativo dos e-mails, é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517619
Algoritmos e Estrutura de Dados
O cientista de dados Pedro trabalha em um projeto que envolve a
previsão dos movimentos de um braço robótico em um ambiente
complexo. Pedro tem um fluxograma de um algoritmo de
aprendizado por reforço que é capaz de se adaptar
dinamicamente ao ambiente e ajustar suas ações com base nos
resultados de ações anteriores.
O algoritmo representado pelo referido fluxograma que deve ser empregado para a realização da tarefa de Pedro é o:
O algoritmo representado pelo referido fluxograma que deve ser empregado para a realização da tarefa de Pedro é o:
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Júnior I - Operação de Sistemas Espaciais Embarcados |
Q2516990
Algoritmos e Estrutura de Dados
Com relação à formulação de algoritmos e suas formas de representação, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) O refinamento passo a passo de cima para baixo é um processo para refinar o pseudocódigo, mantendo uma representação completa do programa durante cada refinamento.
( ) A técnica conhecida como “repetição controlada por contador” é muitas vezes denominada como “repetição definida”, porque o número de repetições é conhecido antes do laço começar a ser executado.
( ) O fluxograma é uma representação gráfica de um algoritmo. É desenhado com alguns símbolos especiais, como retângulos, elipses, círculos e losangos, conectados por setas.
As afirmativas são, respectivamente,