Questões de Concurso
Comentadas para sebrae-nacional
Foram encontradas 470 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Um analista está trabalhando em um projeto que envolve a análise de dados sobre micro e pequenas empresas no Brasil. Seu objetivo é construir um dashboard no Power BI que mostre a evolução dos negócios em diferentes setores, com métricas como faturamento, número de empregados, e taxa de sobrevivência das empresas ao longo dos anos. Os dados estão armazenados em um banco de dados relacional SQL.
Com base nessa situação hipotética, assinale a opção em que é descrita a abordagem mais eficiente para configurar o Power BI, com a utilização de SQL, de forma que o dashboard seja otimizado para desempenho e atualizado regularmente com novos dados.
Assinale a opção que apresenta corretamente a consulta SQL que
retornará a média de salários por departamento de uma empresa,
considerada uma tabela  com colunas
com colunas 
.
Um profissional de dados foi encarregado de criar um dashboard em Qlik Sense que deverá exibir métricas de vendas por região e por produto em tempo real. Os dados estão armazenados em um banco de dados relacional SQL. Para garantir a melhor performance e a integridade das informações, esse profissional deve considerar como o Qlik Sense se conecta ao banco de dados e como as consultas SQL são estruturadas.
Tendo como referência a situação hipotética apresentada, assinale a opção em que é descrita a abordagem mais eficiente e correta para a consulta dos dados na construção desse dashboard.
Um cientista de dados foi encarregado de criar um dashboard para a equipe de vendas da empresa cujo objetivo é monitorar em tempo real as métricas de desempenho, como volume de vendas, receita e número de clientes novos por região. Os dados estão armazenados em um banco de dados SQL, e esse profissional deverá integrar essas consultas SQL no processo de criação do dashboard.
Considerando a situação hipotética apresentada, assinale a opção em que é descrita a abordagem mais eficiente para garantir que o dashboard seja atualizado em tempo real e que as consultas SQL sejam otimizadas para melhor performance.
Um analista foi encarregado de criar um dashboard que mostre a evolução das vendas trimestrais de uma empresa que utiliza tanto Power BI quanto Qlik Sense e armazena seus dados em um banco de dados SQL. O analista precisa extrair os dados trimestrais de 2023 e criar um dashboard interativo que permita aos usuários filtrar por categoria de produto e região.
Nessa situação hipotética, o referido analista deverá escrever
uma consulta SQL para extrair os dados trimestrais de 2023 e
criar um dashboard no
Um cientista de dados é responsável por criar dashboards interativos para uma empresa que pretende monitorar suas vendas e seu desempenho financeiro. A empresa utiliza tanto o Power BI quanto o Qlik Sense para diferentes departamentos. O cientista de dados precisa criar um dashboard que permita aos usuários filtrar dados por região, produto e período de tempo, além de incluir gráficos de linha, barras e mapas interativos.
Considerando a situação hipotética apresentada, assinale a opção correta em relação às capacidades do Power BI e do Qlik Sense para atender aos requisitos mencionados.
Um analista está criando um dashboard no Power BI para visualizar as vendas mensais de uma empresa e necessita criar uma medida que calcule a média móvel de 3 meses de vendas.
Nessa situação, a fórmula DAX mais adequada para a tarefa
mencionada é
Texto 14A3
Em certa base de dados de e-commerce, as tabelas 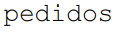 e
e 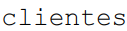 possuem as seguintes estruturas:
possuem as seguintes estruturas:

Um cientista de dados precisa analisar o comportamento de compra dos clientes na base de dados descrita no texto 14A3. O objetivo dessa análise é calcular o valor total gasto por cliente em pedidos feitos no mês anterior ao atual.
Com base nessa situação hipotética, assinale a opção em que
consta o comando que executará corretamente o cálculo
requerido.
Caso um cientista de dados precise extrair, transformar e
analisar grandes volumes de dados em um banco de dados
relacional, usando SQL, a prática mais recomendável para
garantir que as operações de análise sejam eficientes e precisas
consiste em
Em relação aos conceitos do algoritmo k-means, julgue os itens a seguir.
I É importante continuar as iterações do algoritmo k-means até que a mudança na posição dos centroides entre as iterações seja menor que um limite predefinido.
II No coeficiente de silhueta, quanto mais próximo o coeficiente estiver de 1, menor a distância entre os clusters; 0 indica que os dados podem estar no cluster errado; valores negativos sugerem que o ponto está na borda.
III Apesar de um maior número clusters sempre reduzir o SSE (sum of squared errors), isso não significa que mais clusters sempre sejam melhores, pois um número muito grande de clusters pode levar a overfitting do modelo.
Assinale a opção correta.
Em aprendizado de máquina, especialmente em algoritmos de árvores de decisão, é fundamental avaliar como os dados são organizados e classificados em diferentes níveis da árvore. Três conceitos-chave que auxiliam na construção e otimização dessas árvores são o gini impurity, a entropy e o information gain. A respeito desses conceitos, julgue os itens a seguir.
I Gini impurity mede a redução da entropy após a divisão de um conjunto de dados com base em um atributo.
II Entropy mede a quantidade de incerteza ou impureza no conjunto de dados.
III Information gain mede a probabilidade de uma nova instância ser classificada incorretamente, com base na distribuição de classes no conjunto de dados.
Assinale a opção correta.
O conjunto de dados {0, 4, 3, 3, 0} é uma realização de uma amostra aleatória simples retirada de uma população binomial com parâmetros n e p, sendo n = 4 e p uma probabilidade desconhecida.
Com base nessas informações, é correto afirmar que a estimativa de máxima verossimilhança para a probabilidade de ocorrência do valor 2 na população em questão é igual a
Se N for uma variável aleatória que siga uma distribuição normal
com média igual a 10 e desvio padrão igual a 5 e se Z =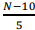 , então a probabilidade de ocorrência do evento “Z = 1,96” será
igual a
, então a probabilidade de ocorrência do evento “Z = 1,96” será
igual a
Supondo-se que a variável aleatória X possa assumir valores 0, 1,
2 ou 3 conforme a função de distribuição de probabilidade P(X = h) = 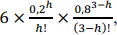 na qual h ∈ {0, 1, 2, 3}, é correto
afirmar que o valor esperado de X seja igual a
na qual h ∈ {0, 1, 2, 3}, é correto
afirmar que o valor esperado de X seja igual a
A respeito do modelo de séries temporais St = ɛt + ɛt-12 + ɛt-24 + ɛt-36 + ... = 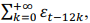 no qual t ∈ ℤ representa um índice temporal e εt denota um erro
aleatório no instante t, que segue uma distribuição normal com
média zero e desvio padrão 5, assinale a opção correta.
no qual t ∈ ℤ representa um índice temporal e εt denota um erro
aleatório no instante t, que segue uma distribuição normal com
média zero e desvio padrão 5, assinale a opção correta.