Questões de Concurso
Sobre amostragem aleatória simples em estatística
Foram encontradas 608 questões
Nesse caso, Y tem distribuição
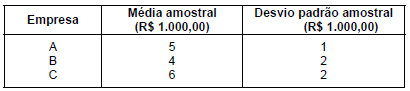
Se k é o valor da estatística F (F calculado) utilizado para testar a igualdade das médias populacionais dos salários dos empregados em A, B e C obtém-se que
Uma análise de mercado com relação às preferências do consumidor referente ao consumo dos sabonetes marcas M e N é realizada por uma empresa mensalmente por meio de experimentos. O diretor comercial da empresa observou que em um experimento 85% dos que consumiram M em um experimento anterior continuaram a consumir M no novo experimento e 60% dos que consumiram N no experimento anterior passaram a consumir M no novo experimento. Considere a matriz de transição abaixo e que este processo esteja sendo realizado ao longo do tempo.

O único vetor de probabilidade fixo t desta matriz é
Deseja-se estimar o total de carboidratos existentes em um lote de 500.000 g de macarrão integral. Para esse fim, foi retirada uma amostra aleatória simples constituída por 5 pequenas porções desse lote, conforme a tabela seguinte, que mostra a quantidade x amostrada, em gramas, e a quantidade de carboidratos encontrada, y, em gramas.

Com base nas informações e na tabela apresentadas, julgue o item a seguir.
Considerando-se o modelo de regressão linear na forma
y = ax + ε, em que ε denota o erro aleatório com média nula e
variância V, e a representa o coeficiente angular, a estimativa
de mínimos quadrados ordinários do coeficiente a é igual ou
superior a 0,5.
Deseja-se estimar o total de carboidratos existentes em um lote de 500.000 g de macarrão integral. Para esse fim, foi retirada uma amostra aleatória simples constituída por 5 pequenas porções desse lote, conforme a tabela seguinte, que mostra a quantidade x amostrada, em gramas, e a quantidade de carboidratos encontrada, y, em gramas.
Com base nas informações e na tabela apresentadas, julgue o item a seguir.
Considerando o estimador de razão, estima-se que existem
250.000 g de carboidratos nesse lote de macarrão integral.
X1, X2, ..., X10 representa uma amostra aleatória simples retirada de uma distribuição normal com média µ e variância σ2 , ambas desconhecidas. Considerando que 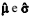 representam os respectivos estimadores de máxima verossimilhança desses parâmetros populacionais, julgue o item subsecutivo.
representam os respectivos estimadores de máxima verossimilhança desses parâmetros populacionais, julgue o item subsecutivo.
A soma X1+ X2 +...+ X10 é uma estatística suficiente para a estimação do parâmetro µ.
A partir da situação hipotética apresentada e considerando Φ(2) = 0,977, em que Φ(z) representa a função de distribuição acumulada de uma distribuição normal padrão e z é um desvio padronizado, julgue o item que se segue, com relação ao teste de hipóteses H0 = µ ≥ 60 minutos, contra HA = µ < 60 minutos, em que H0 e HA denotam, respectivamente, as hipóteses nula e alternativa.
O P-valor (ou nível descritivo do teste) foi superior a 2,3%.
A partir da situação hipotética apresentada e considerando Φ(2) = 0,977, em que Φ(z) representa a função de distribuição acumulada de uma distribuição normal padrão e z é um desvio padronizado, julgue o item que se segue, com relação ao teste de hipóteses H0 = µ ≥ 60 minutos, contra HA = µ < 60 minutos, em que H0 e HA denotam, respectivamente, as hipóteses nula e alternativa.
Nesse teste de hipóteses, comete-se o erro do tipo II caso a
hipótese H0 seja rejeitada, quando, na verdade, H0 não deveria
ser rejeitada.
Uma empresa encomenda uma pesquisa de mercado que utilize o método de amostragem aleatória simples.
Esse é um caso de amostra probabilística em que cada entrevistado
Com o objetivo de avaliar a eficácia de um discurso político na opinião dos eleitores, foi realizado um grupo focal que avaliou as reações de uma amostra de eleitores sobre o discurso. A ideia é medir a significância das mudanças de opinião nos ouvintes, resultantes do discurso. A Tabela abaixo apresenta os movimentos dos pareceres dos 30 ouvintes que participaram do estudo.
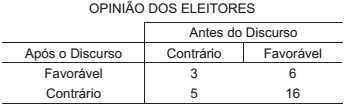
A hipótese nula de indiferença dos eleitores na amostra em relação ao discurso deverá ser refutada para valores da estatística acima de 3,8, a 5% de significância.
Assim sendo, com base nos resultados da amostra, conclui-se
que o discurso
Um modelo de regressão linear simples, Y = β0 + β1 X + ε, foi aplicado para explicar o consumo de um certo bem em função da taxa de desemprego. Uma amostra aleatória de tamanho 40 foi selecionada e forneceu a informação de que, para cada elevação de 1% na taxa de desemprego, a demanda diminui em 1.000 unidades. A tabela de ANOVA apresenta informações para testar a significância do modelo, fornecendo a estatística do teste F = 400 com Fsig = 9,0 × 10-22.
O valor da estatística t de Student para o teste da significância de β1 é
Considere o modelo de regressão linear múltipla com intercepto, da variável dependente Y sobre as p variáveis independentes (X1 , X2 , ..., Xp ), na forma matricial:
E(Y) = X.β
Utilizando uma amostra de tamanho n, obtemos o estimador
dos mínimos quadrados ordinários  =(XTX)-1
XTY. Os
valores estimados de Y,
=(XTX)-1
XTY. Os
valores estimados de Y, 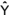 =X
=X , podem ser expressos por
meio de
, podem ser expressos por
meio de 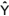 = X.(XTX)-1
XTY.
= X.(XTX)-1
XTY.
Fazendo H = X.(XTX)-1
XT, tem-se 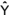 =H.Y, sendo a matriz
n x n, H, denominada matriz de projeção, isto é, a matriz
que projeta o vetor das observações amostrais, Y, no espaço
dos valores estimados
=H.Y, sendo a matriz
n x n, H, denominada matriz de projeção, isto é, a matriz
que projeta o vetor das observações amostrais, Y, no espaço
dos valores estimados 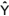 .
.
Diante das considerações feitas acima, observe as afirmações a seguir.:
I - H é uma matriz idempotente.
II -
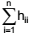 = rank(X) = p , onde hii é o io
elemento da diagonal
da matriz H.
= rank(X) = p , onde hii é o io
elemento da diagonal
da matriz H.
III - H.(I – H) = O, onde I é a matriz identidade e O, a matriz nula.
IV - e = (I – H).Y, onde e é o vetor dos resíduos amostrais.
Está correto o que se afirma em:
Uma amostra aleatória simples de tamanho n foi extraída
de modo independente de uma população com distribuição
normal com parâmetros μ e σ, ambos desconhecidos,
a fim de se estimar a variância, σ2
, da característica de
interesse, Y. O estimador de máxima verossimilhança da amostra foi obtido e expresso por 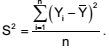
Se 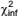 e
e 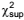 são os limites inferior e superior da distribuição
qui-quadrado com probabilidade (1 – α)100% de
se obter um valor entre eles, então para esse nível de
confiança, uma estimativa não tendenciosa, por intervalo,
para a variância da população é
são os limites inferior e superior da distribuição
qui-quadrado com probabilidade (1 – α)100% de
se obter um valor entre eles, então para esse nível de
confiança, uma estimativa não tendenciosa, por intervalo,
para a variância da população é
Uma amostra aleatória de tamanho n deve ser extraída
de uma população infinita a fim de se estimar a proporção
da população, 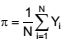 , por meio da estatística
Proporção da Amostra,
, por meio da estatística
Proporção da Amostra, 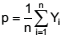 , sendo Yi
uma variável aleatória Bernoulli (π).
, sendo Yi
uma variável aleatória Bernoulli (π).
Na falta de conhecimento prévio da variância do estimador, optou-se por calcular o tamanho da amostra conservador, considerando uma variância máxima, para um nível de confiança de aproximadamente 95%, e um erro amostral absoluto máximo de um ponto percentual.
Com esses parâmetros, o valor mais aproximado para o
tamanho final da amostra é
Uma amostra aleatória de tamanho n > 1 foi extraída independentemente,
sem reposição, de uma população de
tamanho N com distribuição Bernoulli (π ), a fim de se estimar
o total,  , de unidades na população com a característica
A.
, de unidades na população com a característica
A.
Um estimador não tendencioso de  é definido como:
é definido como: