Questões de Concurso
Sobre inferência estatística em estatística
Foram encontradas 1.129 questões
Um teste de hipótese será feito com base numa distribuição normal, com média desconhecida e variância σ2 =64 Uma amostra de tamanho n = 16 é extraída e sua média calculada,sendo X = 7 O conjunto de hipóteses a ser testado é:
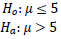
Considere ainda que a região crítica do teste é RC = (9 ,+ ∞) que, caso Ho seja falsa, o μ verdadeiro seria igual a 8.Além disso, são fornecidos os seguintes dados sobre a função distribuição acumulada da normal-padrão.
Φ(0,5) ≅ 0,69 Φ(1) ≅ 0,84 Φ(1,5) ≅ 0,93 Φ(2) ≅ 0,98
Logo, as probabilidades dos erros do Tipo I, do Tipo II e do p-valor (bilateral) do teste são, respectivamente, iguais a:
Com o objetivo de estimar, por intervalo, a verdadeira média populacional de uma distribuição, é extraída uma amostra aleatória de tamanho n = 26. Sendo a variância desconhecida, calcula-se o valor de 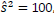 além da média amostral X = 8 de grau de confiança pretendido é de 95%. Somam-se a todas essas informações os valores tabulados:
além da média amostral X = 8 de grau de confiança pretendido é de 95%. Somam-se a todas essas informações os valores tabulados:
Φ(1,65) ≅ 0,95 Φ(1,96) ≅ 0,975 T25(1,71) ≅ 0,95
T26(1,70) ≅ 0,95 T25(2,06) ≅ 0,975 T26(2,05) ≅ 0,975
Onde, 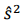 = estimador não-viesado da variância populacional;
= estimador não-viesado da variância populacional;
Φ(z) = fç distribuição acumulada da Normal-padrão;
Tn(t)= fç distribuição acumulada da T-Student com n graus de liberdade.
Então os limites do intervalo de confiança desejado são:
Com a finalidade de estimar a proporção p de indivíduos de certa
população, com determinado atributo, através da proporção
amostral 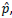 é extraída uma amostra de tamanho n, grande,
compatível com um erro amostral de ɛ e com um grau de
confiança de (1-α). Assim, é correto afirmar que:
é extraída uma amostra de tamanho n, grande,
compatível com um erro amostral de ɛ e com um grau de
confiança de (1-α). Assim, é correto afirmar que:
Com o objetivo de utilizar as suas aeronaves de um modo mais eficiente, uma determinada empresa aérea deseja aplicar um mesmo modelo de otimização para as suas diferentes rotas. Entretanto, esse mesmo modelo só funcionará, principalmente, se as variâncias dessas diferentes rotas puderem ser consideradas as mesmas. Para simplificar, a empresa aérea decidiu comparar apenas duas das suas rotas, que possuem os seguintes dados anuais:
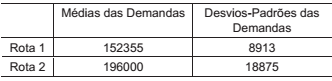
De acordo com os dados acima, foi realizado o seguinte teste de Hipóteses para um teste de significância α = 5%:
H0 : σ12 =σ22
H1 : σ12 ≠ σ22
Além disso, os tamanhos das amostras usadas para se
obter as médias e desvios-padrões acima foram de 25 e
30 para as amostras 1 e 2, respectivamente. Aplicando o
teste de Hipótese, pode-se então concluir que:
Suponha que um estatístico necessita tomar uma amostra aleatória de uma população finita com tamanho N de modo a poder estimar um parâmetro θ com precisão d e com confiança de (1 - α) Seja z o escore normal padronizado correspondente ao nível de confiança, ou seja, a área até 1 - α/2 e admitindo por trabalhos anteriores que o desvio padrão populacional é conhecido e igual a σ, o tamanho da amostra é
Seja a amostra aleatória de tamanho n, [x1, x2, x3, ... , xn ], tomada de uma distribuição de Poisson com parâmetro θ, na busca do Estimador de Verossimilhança desse parâmetro θ, o logaritmo da Função de Verossimilhança é
O erro médio quadrático é uma medida do desempenho de um estimador de um parâmetro θ ou de uma função desse parâmetro, q(θ). A definição do erro médio quadrático é R(θ ,T) = E[T(x) - q(θ)]2 , onde T(x) é o estimador de q(θ). Então, é possível afirmar que
Suponha que você quer comparar o consumo de combustível de carros americanos (1), coreanos (2) e japoneses (3) e obteve os resultados de um delineamento com modelo Yij = μ + αi + εij , onde i = 1, 2, 3 e j = 1, 2, ..., n com os parâmetros: μ média geral, αi i = 1, 2, 3 efeito do nível i do fator (origem do carro) e εij o erro aleatório da observação do consumo do carro j no nível i. Então, para testar a hipótese nula H0 : μ1 = μ2 = μ3 (na média, os carros de origem diferentes são iguais no consumo), a técnica estatística adequada e as condições necessárias à sua aplicação são
Um produto eletrônico tem o seu tempo de garantia modelado por uma distribuição Exponencial. Uma amostra com tamanho n = 100 itens do produto, obtida da assistência técnica, forneceu média amostral de 3,505 anos. A direção da empresa deseja saber qual é o percentual de itens que receberiam manutenção por falha após a entrega do produto se fosse concedida uma garantia de 48 meses. O estatístico da empresa fez os cálculos e afirma que o percentual de itens sujeitos à manutenção é de
A estrutura de correlação do vetor aleatório
com dimensão é dada pela
matriz
Então, as componentes
principais correspondentes são:
Seja o modelo de regressão linear , em que Y é o vetor das respostas (variável dependente) de
dimensão n, X é matriz do modelo de ordem n x p,
é o vetor de parâmetros de dimensão p e
é o vetor
dos erros de dimensão n. Então, admitindo que os erros são i.i.d. com distribuição Normal (Gaussiana)
com média zero e variância σ2, o estimador de mínimos quadrados ordinários do vetor de parâmetros
e o pivô usado para testar a hipótese nula H0i: βi = 0 i = 0, 1, 2, ..... p-1 são, respectivamente,
A detecção de pontos com grande influência
no ajuste de um modelo linear aos dados,
Y = , é feita usando-se a denominada
matriz chapéu H. No caso de se considerar
apenas os valores das variáveis explicativas
Xi i= 1, 2, ..... , p-1, trabalha-se com os
elementos da diagonal principal. Então, a
matriz chapéu é dada por:
No planejamento de uma carta de controle,
é necessário especificar o tamanho da
amostra que será tomada sistematicamente
do processo de produção, bem como a
frequência da amostragem. Em uma Curva
Característica de Operação, CCO, é fácil
ver que amostras com tamanhos maiores
facilitarão a tarefa de detectar aumentos ou
diminuição na média do processo. Considere
a CCO para carta de controle a três desvios
padrões, com desvio padrão σ suposto
conhecido. Se a média do processo salta
do valor de controle μ0, para outro valor
μ1 = μ0 + kσ, a probabilidade da carta não
detectar esta mudança na primeira amostra
após esta ocorrência é chamada de risco
β (ou erro β) e é dada por
Quando se ajusta a uma série temporal um modelo da estrutura médias móveis, a condição fundamental é que a série seja
O Teorema de Neyman-Pearson é usado para determinar a Melhor Região Crítica, C, um conjunto do espaço amostral Rn, de tamanho α, para testar
A enfermeira que tem a função de fazer as compras para um hospital deseja verificar se o tubo que é rosqueado em certo equipamento tem realmente o diâmetro informado pelo fabricante, ou seja, μ0 = 3,0 cm. Ela aceita que o desvio padrão σ informado pelo fabricante está correto e, então, resolve tomar uma amostra aleatória e fazer um teste estatístico para verificar se o fabricante está correto na sua afirmação quanto à média. Para isto, ela fixou: o nível de confiança da estimativa em 1 – α e o erro da estimativa em d. Nessas condições, o cálculo do tamanho da amostra, considerando a amostra infinita, deve partir
Uma oftalmologista tem razões para crer que existe um percentual de crianças com glaucoma em uma escola rural. Desejando estimar esse parâmetro para fins de logística operacional do tratamento, necessita de uma amostra aleatória do grupo de alunos da escola. O número de alunos é conhecido e igual a N. A oftalmologista, então, fixou: o nível de confiança da estimativa em 1 – α, o erro da estimativa em d e uma amostra piloto com tamanho ηo. Nessas condições, o cálculo do tamanho da amostra deve partir
Dados pareados consistem em duas amostras de igual tamanho, onde cada membro de uma das amostras está pareado com o membro correspondente da outra amostra. Este tipo de dados surge, por exemplo, em experimentos planejados para investigar o efeito de um tratamento. Dados pareados também surgem naturalmente quando, nas n unidades experimentais, existem duas medidas, ou seja, um valor pré-tratamento e outro valor pós-tratamento e se deseja saber se existe efeito do tratamento. Neste caso, cada indivíduo serve como o seu próprio controle. Então, é correto afirmar que
Existem duas versões para o teste “t” de Student aplicado a dois grupos, a versão clássica e a versão de Aspin-Welch. Geralmente, toma-se uma amostra de tamanho n1 do primeiro grupo e outra de tamanho n2 do segundo grupo. A seguir calculam-se as médias amostrais, os desvios padrões amostrais e a estatística do teste. Para decidir a versão do teste a ser aplicada, o correto é