Questões de Concurso
Sobre inferência estatística em estatística
Foram encontradas 1.129 questões
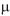 e variância igual a 36 mL2, qualquer que seja o valor de
e variância igual a 36 mL2, qualquer que seja o valor de 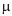 . A máquina foi regulada para
. A máquina foi regulada para 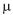 = 290 mL. Semanalmente, uma amostra de 9 garrafas é colhida para verificar se a máquina está ou não desregulada para mais ou para menos. Para isso, constrói-se um teste de hipótese bilateral no qual
= 290 mL. Semanalmente, uma amostra de 9 garrafas é colhida para verificar se a máquina está ou não desregulada para mais ou para menos. Para isso, constrói-se um teste de hipótese bilateral no qual
O nível de significância do teste foi fixado em . A hipótese nula não será rejeitada se a média apresentada pela amostra estiver entre 285,66 mL e 294,34 mL. Logo,
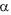 é igual a
é igual a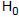 : ? = 100 e
: ? = 100 e 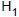 : ? < 100, sendo que
: ? < 100, sendo que 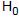 é a hipótese nula,
é a hipótese nula, 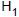 é a hipótese alternativa e ? é a média da população considerada de tamanho infinito com uma distribuição normal. O desvio padrão populacional é igual a 10 horas e utilizou-se a informação da distribuição normal padrão (Z), segundo a qual a probabilidade P(Z ? 1,64) = 5%.
é a hipótese alternativa e ? é a média da população considerada de tamanho infinito com uma distribuição normal. O desvio padrão populacional é igual a 10 horas e utilizou-se a informação da distribuição normal padrão (Z), segundo a qual a probabilidade P(Z ? 1,64) = 5%. 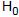 foi rejeitada com base em uma amostra aleatória de 64 componentes em um nível de significância de 5%. Então, o valor da média amostral foi, em horas, no máximo,
foi rejeitada com base em uma amostra aleatória de 64 componentes em um nível de significância de 5%. Então, o valor da média amostral foi, em horas, no máximo, 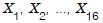 e calculadas as estatísticas
e calculadas as estatísticas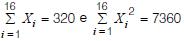
O valor da estatística t (a ser comparado com o ponto desejado da distribuição t de Student) para o teste é:
P(Z > 1,64) = 0,05, P(Z > 2) = 0,02, P(0 < Z < 2,4) = 0,49, P(0 < Z < 0,68) = 0,25
Se t tem distribuição de Student com 3 graus de liberdade P(t > 1,638) = 0,10
Se t tem distribuição de Student com 4 graus de liberdade P(t > 1,533) = 0,10
 : µ = 2 contra H
: µ = 2 contra H : µ > 2 tomou-se uma amostra aleatória de 4 observações que forneceu os valores: 4, 2, 2 e 2. A um nível de significância de 10%, no teste mais poderoso, a hipótese H
: µ > 2 tomou-se uma amostra aleatória de 4 observações que forneceu os valores: 4, 2, 2 e 2. A um nível de significância de 10%, no teste mais poderoso, a hipótese H será rejeitada se a estatística média amostral
será rejeitada se a estatística média amostral  , apropriada ao teste, for maior ou igual a
, apropriada ao teste, for maior ou igual a 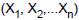 de uma variável aleatória X com função densidade de probabilidade
de uma variável aleatória X com função densidade de probabilidade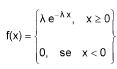
O estimador de máxima verossimilhança de ? é
aleatória simples
 , ...,
, ...,  será retirada de uma distribuição W
será retirada de uma distribuição Wcuja função densidade é
 , em que
, em que 
é um parâmetro desconhecido e exp(1) = 2,72.
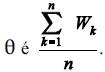
entre o logaritmo do valor pago em um processo judicial de
natureza trabalhista (Y) e o correspondente logaritmo do valor da
causa (X). Para o estudo, foram selecionados ao acaso 301
processos judiciais trabalhistas. Observando-se o par de valores

foram obtidos os resultados apresentados na tabela a seguir.

A partir dessas informações, julgue os itens de 86 a 95,
considerando um modelo de regressão linear simples na forma

é uma doença ocupacional em motoristas profissionais de
transporte rodoviário de carga. Para esse estudo, foram
considerados certos pacientes com idade entre 30 a 50 anos, de
um grande hospital público, formando-se dois grupos: o grupo
dos casos, formado pelos pacientes que tinham hérnia de disco;
e o grupo de controle, formado por aqueles que não tinham hérnia
de disco. Em seguida, foram identificados aqueles que eram
motoristas profissionais. Os resultados estão apresentados na
tabela a seguir.

Considerando essa situação hipotética, julgue os itens seguintes.
é uma doença ocupacional em motoristas profissionais de
transporte rodoviário de carga. Para esse estudo, foram
considerados certos pacientes com idade entre 30 a 50 anos, de
um grande hospital público, formando-se dois grupos: o grupo
dos casos, formado pelos pacientes que tinham hérnia de disco;
e o grupo de controle, formado por aqueles que não tinham hérnia
de disco. Em seguida, foram identificados aqueles que eram
motoristas profissionais. Os resultados estão apresentados na
tabela a seguir.
Considerando essa situação hipotética, julgue os itens seguintes.

 representa o tempo gasto
representa o tempo gastopelo k-ésimo oficial de justiça para o cumprimento de um
mandado judicial. Essas variáveis aleatórias são independentes e
identicamente distribuídas, segundo uma distribuição normal com
média m e desvio padrão d, ambos desconhecidos.
A partir dessas informações, julgue os itens de 69 a 76,
considerando que
 represente a média amostral desse conjunto
represente a média amostral desse conjuntode variáveis aleatórias.
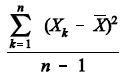 é o estimador de máxima verossimilhança para d
é o estimador de máxima verossimilhança para d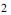 .
. para testar a hipótese nula
 : r = 0,1 contra a hipótese alternativa
: r = 0,1 contra a hipótese alternativaH1: r
 0,1, em que r representa a proporção de desistências em
0,1, em que r representa a proporção de desistências emações judiciais. De uma amostra aleatória simples de 100 casos,
foram encontradas desistências em 17 casos.
Considerando essa situação, julgue os itens seguintes assumindo
que
 (2,6) = 0,995, em que
(2,6) = 0,995, em que  (z) representa a função de
(z) representa a função dedistribuição acumulada da distribuição normal padrão.
para testar a hipótese nula
: r = 0,1 contra a hipótese alternativaH1: r
0,1, em que r representa a proporção de desistências emações judiciais. De uma amostra aleatória simples de 100 casos,
foram encontradas desistências em 17 casos.
Considerando essa situação, julgue os itens seguintes assumindo
que
(2,6) = 0,995, em que (z) representa a função dedistribuição acumulada da distribuição normal padrão.
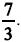
com parâmetro p, em que p é a probabilidade de uma ação
judicial trabalhista ser julgada improcedente. De uma amostra
aleatória simples de 1.600 ações judiciais trabalhistas, uma
seguradora observou que, em média, 20% dessas ações foram
julgadas improcedentes.
Com base nessa situação hipotética, julgue os próximos itens.
Considere as asserções a seguir.
A região de rejeição de um teste de hipóteses é obtida sob a suposição de que a hipótese da nulidade (H0) é verdadeira.
PORQUE
Em testes de hipóteses, o erro do tipo I é aquele cometido ao se rejeitar a hipótese da nulidade (H0) quando esta é verdadeira.
Analisando-se as asserções, conclui-se que
As questões de nos 41 a 46 são referentes aos resultados do ENADE 2006, disponíveis em www.inep.gov.br.
Responda às questões de nos 41 a 43 com base nos percentuais das respostas de alunos de uma área específica de determinada Instituição de Ensino Superior (IES), participantes do ENADE 2006, a algumas questões do questionário socioeconômico relativas aos hábitos de leitura.
Com base nesses resultados, são feitas as afirmativas a seguir.
I - Os alunos dessa IES, proporcionalmente, leram mais livros do que os demais alunos do mesmo curso no país.
II - A maioria dos alunos dessa área nessa IES tem o hábito de ler todos os assuntos dos jornais.
III - Os resultados observados na questão 24 podem ser representados graficamente por um histograma.
IV- Mais da metade dos alunos da região em que se encontra a IES leram, pelo menos, três livros no presente ano.
V - Os alunos dessa IES lêem menos livros técnicos do que os demais alunos da mesma área no estado da IES.
São corretas APENAS as afirmações
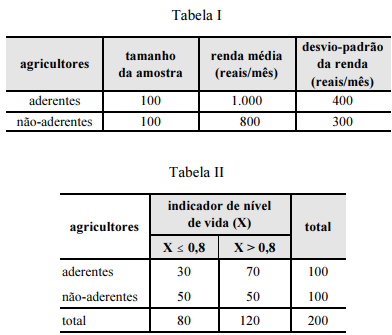
O erro padrão da renda média relativa à distribuição dos agricultores não-aderentes ao PRONAF é inferior a R$ 50,00.
Antes de essa empresa lançar a campanha em âmbito nacional, ela realizou um estudo-piloto em um pequeno número de indústrias, adotando o seguinte plano amostral. De um cadastro de indústrias, foram selecionadas aleatoriamente 2 indústrias e nelas aplicaram-se as campanhas propostas pela instituição, envolvendo todos os operários que lá trabalhavam na ocasião do estudo. Essas indústrias são chamadas “caso”. Também foram selecionadas aleatoriamente outras 2 indústrias, mas nelas as campanhas não foram aplicadas. Essas são chamadas “controle”. Ao longo de um ano foram registrados os números de operários que sofreram algum tipo de acidente nas quatro indústrias, segundo a tabela abaixo.
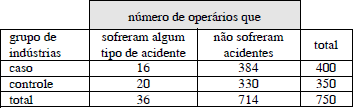
Considere-se que a ocorrência de acidentes segue uma distribuição de Poisson e a hipótese nula (H0) do teste é: “a probabilidade de um operário sofrer algum tipo de acidente é igual a 0,06, mas se um operário for exposto à campanha, a probabilidade de ele, operário, sofrer algum tipo de acidente é reduzida para 0,02”. A hipótese alternativa (Ha) é: “a probabilidade de um operário sofrer algum tipo de acidente é igual a 0,06, independentemente de o operário ter sido ou não exposto à campanha”. Nessa situação, se a estatística qui-quadrado sob H0 for igual a Q0 e se a estatística qui-quadrado sob Ha for igual a Qa, então é correto afirmar que a razão Q0/Qa é a estatística de razão de verossimilhança para o teste em questão.