Questões de Banco de Dados para Concurso
Foram encontradas 15.577 questões
Ano: 2024
Banca:
IV - UFG
Órgão:
Prefeitura de Inhumas - GO
Prova:
CS-UFG - 2024 - Prefeitura de Inhumas - GO - Administrador de Rede e Segurança da Informação |
Q2383865
Banco de Dados
Observe a imagem a seguir.
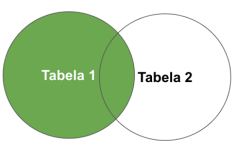
O comando SQL responsável por retornar todos os registros da tabela da esquerda e os registros correspondentes da tabela direita é
O comando SQL responsável por retornar todos os registros da tabela da esquerda e os registros correspondentes da tabela direita é
Ano: 2024
Banca:
IV - UFG
Órgão:
Prefeitura de Inhumas - GO
Prova:
CS-UFG - 2024 - Prefeitura de Inhumas - GO - Administrador de Rede e Segurança da Informação |
Q2383862
Banco de Dados
O comando utilizado para armazenar os valores padrões de
uma coluna no sistema de gerenciamento de banco de
dados PostgreSQL é
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Analista de Suporte |
Q2383489
Banco de Dados
Um sistema gerenciador de banco de dados relacional
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Analista de Sistemas |
Q2383464
Banco de Dados
Considerando o PostgreSQL como gerenciador de banco de
dados, assinale a opção que apresenta os tipos de índices com
melhor desempenho na aceleração de pesquisas de texto
completo.
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383243
Banco de Dados
A paralelização em rotinas de ciência de dados traz benefícios importantes, especialmente quando é necessário
tratar uma grande quantidade de dados.
O principal motivador para paralelizar uma rotina é
O principal motivador para paralelizar uma rotina é
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383239
Banco de Dados
Considere o seguinte texto sobre integração de dados.
Como viabilizar o compartilhamento efetivo de dados e informações das cadeias agropecuárias entre instituições de governo e dessas com a sociedade? Esta foi a principal questão que os participantes do 1º Painel de Cadeias Agropecuárias e Dados Abertos buscaram responder na tarde de quinta-feira (2/12), durante webinar realizado pelo Instituto de Pesquisa Econômica Aplicada (Ipea).
Disponível em: https://www.ipea.gov.br/portal/categorias/45-todas-as-noticias/noticias/11394-especialistas-debatem-abertura- -e-integracao-de-dados-de-cadeias-agropecuarias?highlight= WyJhYmFzdGVjaW1lbnRvIiwiYWd1YSIsIidcdTAwZTFndWEiLCJhZ3VhJywiXQ==. Acesso em: 5 jan. 2024.
Considerando-se o questionamento apresentado no texto e sabendo-se que, quando da integração de conjuntos de dados de múltiplas fontes, matching é uma questão relevante, o problema de identificação de entidades em múltiplas fontes de dados remete ao desafio de
Como viabilizar o compartilhamento efetivo de dados e informações das cadeias agropecuárias entre instituições de governo e dessas com a sociedade? Esta foi a principal questão que os participantes do 1º Painel de Cadeias Agropecuárias e Dados Abertos buscaram responder na tarde de quinta-feira (2/12), durante webinar realizado pelo Instituto de Pesquisa Econômica Aplicada (Ipea).
Disponível em: https://www.ipea.gov.br/portal/categorias/45-todas-as-noticias/noticias/11394-especialistas-debatem-abertura- -e-integracao-de-dados-de-cadeias-agropecuarias?highlight= WyJhYmFzdGVjaW1lbnRvIiwiYWd1YSIsIidcdTAwZTFndWEiLCJhZ3VhJywiXQ==. Acesso em: 5 jan. 2024.
Considerando-se o questionamento apresentado no texto e sabendo-se que, quando da integração de conjuntos de dados de múltiplas fontes, matching é uma questão relevante, o problema de identificação de entidades em múltiplas fontes de dados remete ao desafio de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383236
Banco de Dados
Considere um conjunto de dados que inclui as variáveis
idade, altura e peso. Os dados de idade estão entre 0 e
100 anos, os dados de altura estão entre 1,50 e 2,00 metros e os dados de peso estão entre 50 e 100 kg.
Qual das seguintes técnicas de normalização numérica é mais adequada para esse conjunto de dados?
Qual das seguintes técnicas de normalização numérica é mais adequada para esse conjunto de dados?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383235
Banco de Dados
A deduplicação de dados é uma técnica importante no gerenciamento de informações, especialmente em ambientes onde grandes volumes de dados são gerados e armazenados. Essa técnica é necessária em ambientes onde
grandes volumes de dados são gerados porque pode ajudar a reduzir o consumo de armazenamento e a aumentar
a eficiência dos processos de análise de dados.
A deduplicação de dados é útil, por exemplo, no domínio da medicina, em que há grandes conjuntos de dados genômicos que são analisados para identificar padrões e mutações associadas a doenças específicas. Nesse cenário, a deduplicação é vital para assegurar a precisão das análises, pois, se amostras de DNA de um mesmo paciente são coletadas e sequenciadas em diferentes momentos e locais, pode haver uma repetição inadvertida dessas amostras no banco de dados. Nesse contexto, a deduplicação de dados é crucial para a integridade da pesquisa, pois dados duplicados podem levar a interpretações errôneas, como a superestimação da prevalência de uma mutação genética rara.
A técnica de deduplicação de dados consiste em um processo de
A deduplicação de dados é útil, por exemplo, no domínio da medicina, em que há grandes conjuntos de dados genômicos que são analisados para identificar padrões e mutações associadas a doenças específicas. Nesse cenário, a deduplicação é vital para assegurar a precisão das análises, pois, se amostras de DNA de um mesmo paciente são coletadas e sequenciadas em diferentes momentos e locais, pode haver uma repetição inadvertida dessas amostras no banco de dados. Nesse contexto, a deduplicação de dados é crucial para a integridade da pesquisa, pois dados duplicados podem levar a interpretações errôneas, como a superestimação da prevalência de uma mutação genética rara.
A técnica de deduplicação de dados consiste em um processo de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383234
Banco de Dados
A partir de dados da pesquisa Perfil do Processado e
Produção de Provas nas Ações Criminais por Tráfico de
Drogas, realizada em dezembro de 2023 pelo Instituto de
Pesquisa Econômica Aplicada (Ipea), é possível levantar
informações sociodemográficas sobre os bairros em que
o direito à inviolabilidade domiciliar é relativizado. Os resultados revelam que os bairros mais ricos e aqueles de
população predominantemente branca são praticamente
imunes às entradas em domicílio, as quais se concentram
substancialmente nos bairros mais pobres e naqueles
com população predominantemente negra ou minoritariamente branca.
Qual técnica de desidentificação de dados sensíveis é a mais adequada para preservar a privacidade dos indivíduos processados, permitindo, ainda, a análise sociodemográfica dos bairros?
Qual técnica de desidentificação de dados sensíveis é a mais adequada para preservar a privacidade dos indivíduos processados, permitindo, ainda, a análise sociodemográfica dos bairros?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383232
Banco de Dados
A limpeza de dados, data cleansing, é uma tarefa importante que pode ser complexa e demorada, no entanto é
um investimento fundamental que pode melhorar a qualidade e a utilidade dos dados para futuras análises.
Seja um conjunto de dados com informações de saúde referentes a uma população. Pode-se limpar esses dados para identificar e tratar valores extremos, discrepantes, contraditórios ou inválidos. Com isso, há maior confiabilidade para estimar a prevalência, a incidência, a mortalidade e os fatores de risco de uma doença naquela população representada por aqueles dados.
Por exemplo, seja o conjunto de dados abaixo referente a uma amostra de 5 indivíduos em uma mesma cidade, na qual um analista percebeu a necessidade de limpeza de dados por conta de potenciais inconsistências.
Indivíduo 1: Sexo: Feminino; Idade: 8 anos; Altura: 1,15m; Peso: 40kg; Batimento Cardíaco em Repouso: 85 bpm
Indivíduo 2: Sexo: Masculino; Idade: 22 anos; Altura: 1,60m; Peso: 60kg; Batimento Cardíaco em Repouso: 72 bpm
Indivíduo 3: Sexo: Feminino; Idade: 40 anos; Altura: 1,60m; Peso: 55kg; Batimento Cardíaco em Repouso: 10 bpm
Indivíduo 4: Sexo: Masculino; Idade: 55 anos; Altura: 1,90m; Peso: 100kg; Batimento Cardíaco em Repouso: 70 bpm
Indivíduo 5: Sexo: Feminino; Idade: 70 anos; Altura: 1,50m; Peso: 60kg; Batimento Cardíaco em Repouso: 70 bpm
Qual ação é a única claramente necessária para realizar data cleansing neste conjunto de dados específico?
Seja um conjunto de dados com informações de saúde referentes a uma população. Pode-se limpar esses dados para identificar e tratar valores extremos, discrepantes, contraditórios ou inválidos. Com isso, há maior confiabilidade para estimar a prevalência, a incidência, a mortalidade e os fatores de risco de uma doença naquela população representada por aqueles dados.
Por exemplo, seja o conjunto de dados abaixo referente a uma amostra de 5 indivíduos em uma mesma cidade, na qual um analista percebeu a necessidade de limpeza de dados por conta de potenciais inconsistências.
Indivíduo 1: Sexo: Feminino; Idade: 8 anos; Altura: 1,15m; Peso: 40kg; Batimento Cardíaco em Repouso: 85 bpm
Indivíduo 2: Sexo: Masculino; Idade: 22 anos; Altura: 1,60m; Peso: 60kg; Batimento Cardíaco em Repouso: 72 bpm
Indivíduo 3: Sexo: Feminino; Idade: 40 anos; Altura: 1,60m; Peso: 55kg; Batimento Cardíaco em Repouso: 10 bpm
Indivíduo 4: Sexo: Masculino; Idade: 55 anos; Altura: 1,90m; Peso: 100kg; Batimento Cardíaco em Repouso: 70 bpm
Indivíduo 5: Sexo: Feminino; Idade: 70 anos; Altura: 1,50m; Peso: 60kg; Batimento Cardíaco em Repouso: 70 bpm
Qual ação é a única claramente necessária para realizar data cleansing neste conjunto de dados específico?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383231
Banco de Dados
Um cientista de dados precisa discretizar uma variável, representando distâncias entre cidades em quilômetros em
10 intervalos com, aproximadamente, o mesmo número
de observações.
Nesse contexto, a técnica mais adequada é a discretização
Nesse contexto, a técnica mais adequada é a discretização
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383230
Banco de Dados
Para a avaliação de políticas públicas na área de Segurança Alimentar e Nutricional, um município brasileiro utilizou dados
persistidos em três relações (tabelas) organizadas de acordo com o seguinte modelo relacional:
PRODUTO (cod-produto, nome-produto, grupo-alimentar) FORNECEDOR (CNPJ, nome-empresa, tipo) COMPRADO (CNPJ, cod-produto, data, quantidade, valor)
Os atributos que formam as chaves primárias de cada tabela estão sublinhados.
Nesse contexto, considere o comando SQL apresentado a seguir.
SELECT P.cod-produto, SUM (quantidade) FROM PRODUTO P, FORNECEDOR F, COMPRADO C WHERE P.cod-produto = C.cod-produto AND C.CNPJ = F.CNPJ AND F.tipo = 'agricultura familiar' GROUP BY P.cod-produto HAVING SUM (quantidade) > 10000
Os resultados produzidos pela execução desse comando apresentam o código do produto e a soma das quantidades compradas dos produtos de
PRODUTO (cod-produto, nome-produto, grupo-alimentar) FORNECEDOR (CNPJ, nome-empresa, tipo) COMPRADO (CNPJ, cod-produto, data, quantidade, valor)
Os atributos que formam as chaves primárias de cada tabela estão sublinhados.
Nesse contexto, considere o comando SQL apresentado a seguir.
SELECT P.cod-produto, SUM (quantidade) FROM PRODUTO P, FORNECEDOR F, COMPRADO C WHERE P.cod-produto = C.cod-produto AND C.CNPJ = F.CNPJ AND F.tipo = 'agricultura familiar' GROUP BY P.cod-produto HAVING SUM (quantidade) > 10000
Os resultados produzidos pela execução desse comando apresentam o código do produto e a soma das quantidades compradas dos produtos de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383229
Banco de Dados
Para um estudo do tema Educação, foram coletados dados de escolas e de professores em todos os municípios brasileiros.
Esses dados foram armazenados em duas relações (tabelas), organizadas de acordo com o seguinte modelo relacional:
ESCOLA (cod-escola, nome-escola, cod-municipio, quantidade-alunos)
PROFESSOR (CPF, nome-prof, data-nascimento, cod-municipio-residencia, cod-escola-prof)
A chave primária de ESCOLA é cod-escola, e a de PROFESSOR é CPF. A coluna cod-escola-prof em PROFESSOR é uma chave estrangeira e indica em que escola o professor leciona. Considere a utilização dos operadores de Projeção (π ou PROJETE), Seleção (σ ou SELECIONE) e Junção ( ou JUNTE) da Álgebra Relacional.
ou JUNTE) da Álgebra Relacional.
Que sequência de operações, em Álgebra Relacional, produz como resultado uma relação R-X com CPF e nome dos professores que NÃO residem no mesmo município onde lecionam?
ESCOLA (cod-escola, nome-escola, cod-municipio, quantidade-alunos)
PROFESSOR (CPF, nome-prof, data-nascimento, cod-municipio-residencia, cod-escola-prof)
A chave primária de ESCOLA é cod-escola, e a de PROFESSOR é CPF. A coluna cod-escola-prof em PROFESSOR é uma chave estrangeira e indica em que escola o professor leciona. Considere a utilização dos operadores de Projeção (π ou PROJETE), Seleção (σ ou SELECIONE) e Junção (
ou JUNTE) da Álgebra Relacional. Que sequência de operações, em Álgebra Relacional, produz como resultado uma relação R-X com CPF e nome dos professores que NÃO residem no mesmo município onde lecionam?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383228
Banco de Dados
Uma das principais características de sistemas gerenciadores de bancos de dados (SGBD) NoSQL, quando comparados aos sistemas gerenciadores bancos de dados
relacionais (SGBDR), é que seu esquema é considerado
flexível ou não existente (schemaless).
O esquema de um SGBD NoSQL ser flexível ou não existente tem como consequência o fato de que
O esquema de um SGBD NoSQL ser flexível ou não existente tem como consequência o fato de que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383227
Banco de Dados
Sistemas Gerenciadores de Bancos de Dados, SGBD,
via de regra, permitem acesso às suas funcionalidades
por meio de interfaces interativas e, também, por meio de
programas de apoio ou comandos específicos. O SGBD
PostgreSQL possui um conjunto de programas de apoio.
O programa a ser utilizado para realizar o backup de um
banco de dados ou de um esquema, no PostgreSQL, é o
pg_dump.
Nesse contexto, considere o seguinte comando:
pg_dump -a -Fp Alfa > Beta
Esse comando gera um backup
Nesse contexto, considere o seguinte comando:
pg_dump -a -Fp Alfa > Beta
Esse comando gera um backup
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383226
Banco de Dados
Nas últimas décadas, a automatização e a inserção de
máquinas agrícolas transformaram profundamente o
panorama do trabalho nas áreas rurais [...] e, em menos de 50 anos, a produtividade do agronegócio brasileiro aumentou 400%. [...]
Esses resultados vieram com a adoção da tecnologia nos processos cotidianos, e também com o investimento em pesquisas [...]. Agora, o agronegócio pode estar diante de um novo salto de produtividade; big data e machine learning são ferramentas que estão ganhando espaço e que podem, novamente, transformar o cenário do campo.
Disponível em: https://summitagro.estadao.com.br/tendencias-e- -tecnologia/como-big-data-e-machine-learning-sao-aplicados-no- -agronegocio/. Acesso em: 5 jan. 2024. Adaptado.
A utilização da plataforma paralela de processamento MapReduce aplica-se adequadamente como um framework de processamento de Big Data, visando à escalabilidade para as aplicações.
Nesse contexto, uma característica inerente à MapReduce é a
Esses resultados vieram com a adoção da tecnologia nos processos cotidianos, e também com o investimento em pesquisas [...]. Agora, o agronegócio pode estar diante de um novo salto de produtividade; big data e machine learning são ferramentas que estão ganhando espaço e que podem, novamente, transformar o cenário do campo.
Disponível em: https://summitagro.estadao.com.br/tendencias-e- -tecnologia/como-big-data-e-machine-learning-sao-aplicados-no- -agronegocio/. Acesso em: 5 jan. 2024. Adaptado.
A utilização da plataforma paralela de processamento MapReduce aplica-se adequadamente como um framework de processamento de Big Data, visando à escalabilidade para as aplicações.
Nesse contexto, uma característica inerente à MapReduce é a
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383225
Banco de Dados
Sistemas de bancos de dados apresentam benefícios e
desafios potencializados quando é possível adotar uma
solução de gerência distribuída, coordenada por um sistema de banco de dados distribuído.
Nesse contexto, uma importante questão de projeto refere-se à
Nesse contexto, uma importante questão de projeto refere-se à
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383224
Banco de Dados
O Banco Nossa Caixa é o primeiro banco do hemisfério sul a implantar o GDPS (Processamento Paralelo em Locais Geograficamente Distantes, na sigla em
inglês), sistema que processa, simultaneamente, todos os dados da instituição em dois locais fisicamente
separados. A tecnologia garante o armazenamento e
a continuidade do funcionamento de todos os canais
de atendimento e de negócios do banco, ainda que a
operação de um dos equipamentos responsáveis por
essas funções seja interrompida por um blecaute ou incêndio, por exemplo. O banco investiu R$ 80 milhões
no projeto, que levou quatro anos desde a concepção
até a implantação.
Do Banco Nossa Caixa
Disponível em: https://www.saopaulo.sp.gov.br/ultimas-noticias/ nossa-caixa-usa-sistema-pioneiro-de-processamento-de-dados/. Acesso em: 5 jan. 2024.
No modelo de arquitetura Massively Parallel Processor, MPP, extensibilidade e escalabilidade são características comuns e vantajosas no armazenamento e no processamento de dados paralelos.
Nesse contexto, qual modelo de processamento se enquadra à arquitetura MPP?
Do Banco Nossa Caixa
Disponível em: https://www.saopaulo.sp.gov.br/ultimas-noticias/ nossa-caixa-usa-sistema-pioneiro-de-processamento-de-dados/. Acesso em: 5 jan. 2024.
No modelo de arquitetura Massively Parallel Processor, MPP, extensibilidade e escalabilidade são características comuns e vantajosas no armazenamento e no processamento de dados paralelos.
Nesse contexto, qual modelo de processamento se enquadra à arquitetura MPP?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383223
Banco de Dados
Apesar de existirem diversas aplicações reais em que há
necessidade de ingestão periódica de dados, em algumas
a ingestão em lote pode não ser vantajosa, como, por
exemplo, em
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383222
Banco de Dados
Para melhorar o processamento de grandes volumes de
dados através de computação paralela ou distribuída,
pode-se utilizar sharding, técnica que divide os dados em
partes menores, chamadas shards. Essas partes são normalmente armazenadas em diferentes nós, ou sítios, de
processamento em um sistema distribuído.
O sharding é necessário para garantir a
O sharding é necessário para garantir a