Questões de Concurso
Comentadas para cesgranrio
Foram encontradas 18.548 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383283
Engenharia de Software
Em uma nota técnica do Ipea sobre emprego público nos
governos subnacionais brasileiros, no ano de 2016, aparece menção sobre o fato de as bases utilizadas possuirem outliers, ou valores atípicos.
A construção de um modelo preditivo a partir dos dados dessas bases, usando árvores aleatórias, Random Forests,
A construção de um modelo preditivo a partir dos dados dessas bases, usando árvores aleatórias, Random Forests,
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383281
Engenharia de Software
Um cientista de dados está utilizando máquinas de vetor
de suporte (SVM) em um projeto de classificação, pois
deseja evitar o overfitting do modelo aos dados de treinamento.
Qual das seguintes técnicas auxilia a prevenir o overfitting em SVM?
Qual das seguintes técnicas auxilia a prevenir o overfitting em SVM?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383280
Engenharia de Software
Em um projeto de classificação de textos, um modelo de
machine learning foi aplicado em um conjunto de teste
e apresentou os seguintes resultados: uma precisão de
80% e uma revocação de 70%.
Com base nessas informações e considerando-se apenas a parte inteira da porcentagem, qual é o F1 Score desse modelo?
Com base nessas informações e considerando-se apenas a parte inteira da porcentagem, qual é o F1 Score desse modelo?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383279
Engenharia de Software
Um pesquisador possui um conjunto de dados consistindo
em características diversas, features, e suas respectivas
classificações, labels. Ele deseja dividir esse conjunto de
dados em conjuntos distintos, para treinamento e para
teste, com o objetivo de validar a eficácia de um modelo
de aprendizado de máquina.
Nesse contexto, qual função do SciKit-learn ele deve utilizar para realizar essa divisão de maneira eficiente e adequada?
Nesse contexto, qual função do SciKit-learn ele deve utilizar para realizar essa divisão de maneira eficiente e adequada?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383278
Engenharia de Software
Uma cientista de dados percebeu que, ao processar alguns documentos, seria melhor remover palavras que
aparecem em quase todo texto, as stop-words.
Para começar sua lista de stop-words, ela pode escolher listar todos os
Para começar sua lista de stop-words, ela pode escolher listar todos os
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383277
Engenharia de Software
O método de POS-tagging, ou Part of Speech tagging, é
uma tarefa do processamento de linguagem natural em
que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383276
Engenharia de Software
Em redes convolucionais, o tamanho do passo normalmente é menor que o tamanho do filtro.
Se o tamanho do passo for maior que o tamanho do filtro, é possível que
Se o tamanho do passo for maior que o tamanho do filtro, é possível que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383275
Engenharia de Software
Na arquitetura de redes neurais, diferentes funções de
ativação são utilizadas nas camadas de neurônios para
aplicar transformações não lineares aos dados. Uma dessas funções é a ReLU, conhecida por sua eficácia em diversos modelos de aprendizado profundo.
Ao implementar a função ReLU, um pesquisador deve seguir a fórmula:
Ao implementar a função ReLU, um pesquisador deve seguir a fórmula:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383273
Engenharia de Software
Em processamento de linguagem natural, o modelo
Skip-Gram é uma técnica popular para treinar word
embeddings.
O treinamento do modelo Skip-Gram destaca-se de outras técnicas, como o Continuous Bag of Words (CBOW), por ter a seguinte característica:
O treinamento do modelo Skip-Gram destaca-se de outras técnicas, como o Continuous Bag of Words (CBOW), por ter a seguinte característica:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383272
Algoritmos e Estrutura de Dados
Um pesquisador iniciante em aprendizado de máquina
trabalhava com um modelo de classificação binário com
as duas classes equilibradas. Inicialmente, ele fez a avaliação de seu modelo, separando 20% dos dados disponíveis para a avaliação, e o treinou com 80% dos dados,
fazendo o processo apenas uma vez. Depois, a pedido
de seu chefe, ele trocou a forma de avaliação, separando o conjunto de dados em 10 partes e escolhendo, em
10 rodadas, uma parte diferente para avaliação e as outras para treinamento.
Essas duas formas de avaliar um modelo são conhecidas, respectivamente, como
Essas duas formas de avaliar um modelo são conhecidas, respectivamente, como
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383268
Estatística
O Quadro abaixo fornece informações sobre o índice de vendas no varejo por estado em agosto de 2023.

Um analista de dados resolveu verificar se há presença de outliers nesse conjunto de índices e decidiu fazer isso por meio de um Box Plot dos dados fornecidos.
Com base na técnica escolhida pelo analista, quantos índices podem ser enquadrados como outliers?
Um analista de dados resolveu verificar se há presença de outliers nesse conjunto de índices e decidiu fazer isso por meio de um Box Plot dos dados fornecidos.
Com base na técnica escolhida pelo analista, quantos índices podem ser enquadrados como outliers?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383267
Estatística
Considere que o salário médio de empregados de um determinado setor de serviços do Brasil é R$ 2.300,00, com um
desvio padrão conhecido de R$ 400,00. Uma empresa desse setor é selecionada ao acaso, e dela é selecionada uma
amostra de 36 funcionários, resultando em um salário médio de R$ 2.500,00. Um pesquisador decide realizar um teste
de hipótese unilateral com um nível de confiança de 95% para verificar se a empresa selecionada paga salários médios
maiores do que a média do setor.
Considere o extrato da Tabela a seguir.
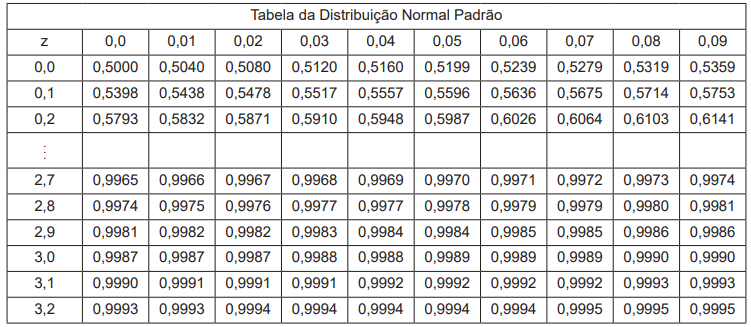
Qual o valor-p do teste aplicado pelo pesquisador?
Considere o extrato da Tabela a seguir.
Qual o valor-p do teste aplicado pelo pesquisador?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383264
Estatística
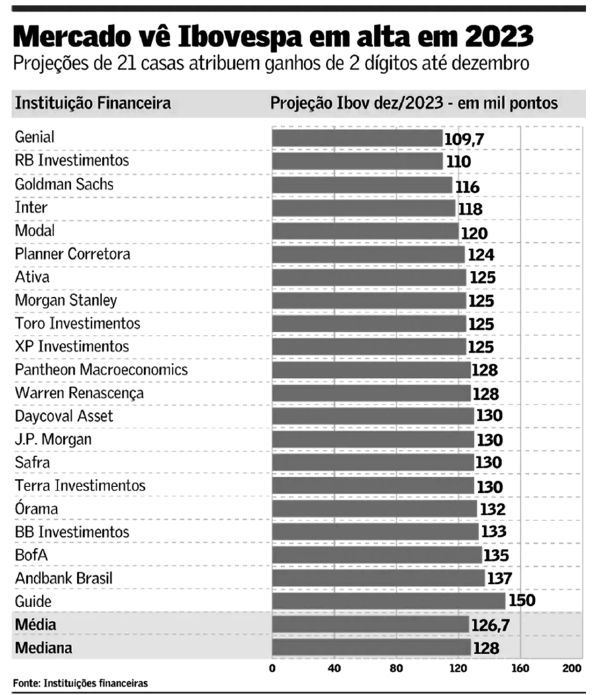
Ao fim do ano de 2022, 21 instituições financeiras fizeram estimativas para o Ibovespa, principal índice de ações da bolsa
brasileira (B3), mostradas na notícia do Jornal Valor Econômico de 22/12/2022, que também apresenta a média aritmética
e a mediana dos dados.
Previsão para a bolsa é de alta em 2023
Casa mais otimista projeta Ibovespa em 150 mil pontos; rumo dos juros será decisivo
Disponível em: https://valor.globo.com/financas/noticia/2022/12/22/previsao-para-a-bolsa-e-de-alta-em-20233.ghtml. Acesso em: 29 dez. 2023. Adaptado.
No útimo pregão do ano de 2023, o Ibovespa fechou em 134.185,23 pontos, conforme dados da B3.
Considerando-se os dados apresentados, a medida de posição das estimativas das instituições financeiras que mais se aproximou do resultado real, apresentado pelo Ibovespa no último pregão do ano, foi a:
Previsão para a bolsa é de alta em 2023
Casa mais otimista projeta Ibovespa em 150 mil pontos; rumo dos juros será decisivo
Disponível em: https://valor.globo.com/financas/noticia/2022/12/22/previsao-para-a-bolsa-e-de-alta-em-20233.ghtml. Acesso em: 29 dez. 2023. Adaptado.
No útimo pregão do ano de 2023, o Ibovespa fechou em 134.185,23 pontos, conforme dados da B3.
Considerando-se os dados apresentados, a medida de posição das estimativas das instituições financeiras que mais se aproximou do resultado real, apresentado pelo Ibovespa no último pregão do ano, foi a:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383263
Estatística
Considere a matéria a seguir, sobre a dura realidade do trabalho infantil no Brasil.
Quase 5% das crianças e adolescentes do país estão em situação de trabalho infantil, aponta IBGE
O Brasil tem um total de 38,365 milhões de pessoas com idade de 5 a 17 anos. Destas, 2,103 milhões realizam atividades econômicas ou de autoconsumo, estando 1,881 milhão em situação de trabalho infantil, o equivalente a 4,9% do total de pessoas entre 5 e 17 anos no país, segundo dados da Pesquisa Nacional por Amostra de Domicílios Contínua 2022, divulgados pelo Instituto Brasileiro de Geografia e Estatística (IBGE). A pesquisa também apontou que, em 2022, 756 mil crianças e adolescentes exerciam atividades da Lista TIP, do governo federal, que elenca as piores formas de trabalho infantil no país. No geral, são serviços que envolvem risco de acidentes ou são prejudiciais à saúde, como trabalho na construção civil, em matadouros, oficinas mecânicas, comércio ambulante em locais públicos, coleta de lixo, venda de bebidas alcoólicas, entre outras atividades.

A pesquisa do IBGE considera duas categorias de atividades:
• econômica, que é a de quem trabalhou pelo menos 1 hora completa e foi remunerado em dinheiro, produtos, benefícios, etc., ou que não teve remuneração direta, mas atuou para ajudar a atividade econômica de algum parente.
• de autoconsumo, que incluem pesca, criação de animais, fabricação de roupas, construção de imóveis e outras que sejam para uso exclusivo da pessoa ou de parentes.
E nem todas as pessoas de 5 a 17 anos que exercem essas atividades se enquadram na situação de trabalho infantil.
Disponível em: https://g1.globo.com/trabalho-e-carreira/noticia/2023/12/20/quase-5percent-das-criancas-e-adolescentes-do-pais-estao-emsituacao-de-trabalho-infantil-aponta-ibge.ghtml. Acesso em: 29 dez 2023. Adaptado.
Nesse contexto, considere que uma pessoa de 5 a 17 anos é escolhida ao acaso e que se deseja estimar a probabilidade de que essa pessoa exerça trabalho infantil, mas não em uma de suas piores formas, que são elencadas na lista TIP, dado que ela realiza atividades econômicas ou de autoconsumo.
Essa probabilidade é, aproximadamente, de
Quase 5% das crianças e adolescentes do país estão em situação de trabalho infantil, aponta IBGE
O Brasil tem um total de 38,365 milhões de pessoas com idade de 5 a 17 anos. Destas, 2,103 milhões realizam atividades econômicas ou de autoconsumo, estando 1,881 milhão em situação de trabalho infantil, o equivalente a 4,9% do total de pessoas entre 5 e 17 anos no país, segundo dados da Pesquisa Nacional por Amostra de Domicílios Contínua 2022, divulgados pelo Instituto Brasileiro de Geografia e Estatística (IBGE). A pesquisa também apontou que, em 2022, 756 mil crianças e adolescentes exerciam atividades da Lista TIP, do governo federal, que elenca as piores formas de trabalho infantil no país. No geral, são serviços que envolvem risco de acidentes ou são prejudiciais à saúde, como trabalho na construção civil, em matadouros, oficinas mecânicas, comércio ambulante em locais públicos, coleta de lixo, venda de bebidas alcoólicas, entre outras atividades.
A pesquisa do IBGE considera duas categorias de atividades:
• econômica, que é a de quem trabalhou pelo menos 1 hora completa e foi remunerado em dinheiro, produtos, benefícios, etc., ou que não teve remuneração direta, mas atuou para ajudar a atividade econômica de algum parente.
• de autoconsumo, que incluem pesca, criação de animais, fabricação de roupas, construção de imóveis e outras que sejam para uso exclusivo da pessoa ou de parentes.
E nem todas as pessoas de 5 a 17 anos que exercem essas atividades se enquadram na situação de trabalho infantil.
Disponível em: https://g1.globo.com/trabalho-e-carreira/noticia/2023/12/20/quase-5percent-das-criancas-e-adolescentes-do-pais-estao-emsituacao-de-trabalho-infantil-aponta-ibge.ghtml. Acesso em: 29 dez 2023. Adaptado.
Nesse contexto, considere que uma pessoa de 5 a 17 anos é escolhida ao acaso e que se deseja estimar a probabilidade de que essa pessoa exerça trabalho infantil, mas não em uma de suas piores formas, que são elencadas na lista TIP, dado que ela realiza atividades econômicas ou de autoconsumo.
Essa probabilidade é, aproximadamente, de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383261
Estatística
Em uma maternidade, 400 bebês nasceram em uma
semana. Sejam H e M os números de meninos e de
meninas, respectivamente. Sabe-se, portanto, que
H + M = 400. Suponha para esse problema que, para
cada bebê, a probabilidade de que seja menino seja exatamente igual a 1/2; suponha também que os sexos dos
bebês sejam perfeitamente independentes uns dos outros. Seja P a probabilidade condicional de que H < 90,
dado que H < 100.
Aproximadamente, quanto vale P?
Aproximadamente, quanto vale P?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383254
Programação
Uma lista é uma estrutura de dados versátil e fundamental usada para organizar e armazenar coleções de itens.
As listas em Python oferecem uma maneira dinâmica e
eficiente de lidar com sequências de itens. Por terem a
capacidade de adicionar, remover e modificar elementos,
essas listas desempenham um papel crucial em muitos
programas em Python, tornando-se uma ferramenta essencial para tarefas que vão desde o armazenamento
simples de dados até algoritmos mais complexos e manipulação de dados.
Nesse contexto, considere duas listas, L1 e L2, que foram implementadas em Python. As configurações iniciais dessas listas são as seguintes:
L1 = [1, 2, 3]
L2 = [3, 4, 5]
Em seguida, foram feitas as seguintes operações:
L1.append(3)
L3 = L1
L3.append(7)
L1.append(8)
L4 = L1 + L2
Qual é o valor de L4?
Nesse contexto, considere duas listas, L1 e L2, que foram implementadas em Python. As configurações iniciais dessas listas são as seguintes:
L1 = [1, 2, 3]
L2 = [3, 4, 5]
Em seguida, foram feitas as seguintes operações:
L1.append(3)
L3 = L1
L3.append(7)
L1.append(8)
L4 = L1 + L2
Qual é o valor de L4?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383253
Programação
Python é dinamicamente tipado, o que significa que os
tipos de variáveis são determinados em tempo de execução com base nos valores atribuídos, proporcionando flexibilidade durante o desenvolvimento. Essa dinamicidade
permite a criação de código versátil e adaptável.
Nesse contexto, considere o seguinte trecho de código:
a = 5
b = 5
c = '5'
d = (a + b) + c
Qual é o resultado da variável d?
Nesse contexto, considere o seguinte trecho de código:
a = 5
b = 5
c = '5'
d = (a + b) + c
Qual é o resultado da variável d?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383252
Programação
Um programa em Python contém um vetor unidimensional, de tamanho 20, chamado vetor, criado com o
Numpy. Deseja-se obter, em apenas uma expressão, uma
matriz de 4 linhas e 5 colunas criada linha a linha a partir
dos elementos desse vetor.
Para tal fim, a expressão a ser utilizada é
Para tal fim, a expressão a ser utilizada é
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383251
Programação
Na programação funcional, que é um paradigma suportado pela Linguagem Scala, uma das práticas fundamentais é o uso
de funções puras.
A principal propriedade que caracteriza uma função pura é a(o)
A principal propriedade que caracteriza uma função pura é a(o)
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383250
Programação
Um cientista de dados recebeu um vetor chamado dados contendo valores da renda mensal da população de uma cidade
e resolveu obter algumas estatísticas que descrevessem os dados recebidos.
A linha de código em R que calcula corretamente a média do vetor dados é
A linha de código em R que calcula corretamente a média do vetor dados é