Questões de Concurso
Foram encontradas 10.221 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410724
Estatística
Nas estatísticas do Poder Judiciário, a taxa de congestionamento (X), que consiste em um indicador que permite medir a efetividade da movimentação processual de um tribunal, é uma variável aleatória contínua com função de densidade f(x) expressa por
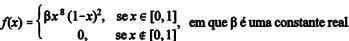
Com base nessas informações, julgue os próximos itens.
A média da taxa de congestionamento é inferior a 0,10 × β.
Com base nessas informações, julgue os próximos itens.
A média da taxa de congestionamento é inferior a 0,10 × β.
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410723
Estatística
Nas estatísticas do Poder Judiciário, a taxa de congestionamento (X), que consiste em um indicador que permite medir a efetividade da movimentação processual de um tribunal, é uma variável aleatória contínua com função de densidade f(x) expressa por
Com base nessas informações, julgue os próximos itens.
O valor de β é superior a 450 e inferior a 500.
Com base nessas informações, julgue os próximos itens.
O valor de β é superior a 450 e inferior a 500.
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410722
Estatística
Nas estatísticas do Poder Judiciário, a taxa de congestionamento (X), que consiste em um indicador que permite medir a efetividade da movimentação processual de um tribunal, é uma variável aleatória contínua com função de densidade f(x) expressa por
Com base nessas informações, julgue os próximos itens.
A variável aleatória X segue uma distribuição especial denominada de Beta, que é, a priori, conjugada das distribuições geométrica e de Bernoulli
Com base nessas informações, julgue os próximos itens.
A variável aleatória X segue uma distribuição especial denominada de Beta, que é, a priori, conjugada das distribuições geométrica e de Bernoulli
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410721
Estatística
Nas estatísticas do Poder Judiciário, a taxa de congestionamento (X), que consiste em um indicador que permite medir a efetividade da movimentação processual de um tribunal, é uma variável aleatória contínua com função de densidade f(x) expressa por
Com base nessas informações, julgue os próximos itens.
A distribuição da taxa de congestionamento X é simétrica em torno de 0,5.
Com base nessas informações, julgue os próximos itens.
A distribuição da taxa de congestionamento X é simétrica em torno de 0,5.
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410720
Estatística

O quadro acima mostra uma síntese da movimentação processual dos tribunais de justiça dos estados de São Paulo, Rio de Janeiro, Minas Gerais, Rio Grande do Sul e do total da justiça estadual no Brasil em 2010. Considere que o estoque de processos em andamento no estado j (Ej ), no final de 2010, seja um indicador que se define como Ej = Xj + Yj - Zj - Wj , em que j = 1, 2, ..., 27; Xj representa o número de casos novos registrados em 2010 no estado j; Yj seja a quantidade de casos pendentes no estado j (i.e., casos anteriores que não foram solucionados até o final de 2010); Zj denota o total de processos baixados (arquivados) no estado j durante 2010 e Wj seja o número de sentenças e decisões proferidas no estado j até o final de 2010. Considere, por fim, que, para todos os efeitos, o Distrito Federal seja um estado. Com base nessas informações e no quadro acima, julgue os itens que se seguem.
Considerando-se que Var(E) seja a variância da distribuição dos estoques de processos existentes nos tribunais estaduais, então Var(E) = Var(X) + Var(Y) - Var(Z) - Var(W).
Considerando-se que Var(E) seja a variância da distribuição dos estoques de processos existentes nos tribunais estaduais, então Var(E) = Var(X) + Var(Y) - Var(Z) - Var(W).
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410719
Estatística
O quadro acima mostra uma síntese da movimentação processual dos tribunais de justiça dos estados de São Paulo, Rio de Janeiro, Minas Gerais, Rio Grande do Sul e do total da justiça estadual no Brasil em 2010. Considere que o estoque de processos em andamento no estado j (Ej ), no final de 2010, seja um indicador que se define como Ej = Xj + Yj - Zj - Wj , em que j = 1, 2, ..., 27; Xj representa o número de casos novos registrados em 2010 no estado j; Yj seja a quantidade de casos pendentes no estado j (i.e., casos anteriores que não foram solucionados até o final de 2010); Zj denota o total de processos baixados (arquivados) no estado j durante 2010 e Wj seja o número de sentenças e decisões proferidas no estado j até o final de 2010. Considere, por fim, que, para todos os efeitos, o Distrito Federal seja um estado. Com base nessas informações e no quadro acima, julgue os itens que se seguem.
O estoque de processos em andamento no estado de São Paulo no final de 2010 representou 37,5% do total dos estoques de processos em andamento nos tribunais estaduais do país nesse mesmo período.
O estoque de processos em andamento no estado de São Paulo no final de 2010 representou 37,5% do total dos estoques de processos em andamento nos tribunais estaduais do país nesse mesmo período.
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410718
Estatística
O quadro acima mostra uma síntese da movimentação processual dos tribunais de justiça dos estados de São Paulo, Rio de Janeiro, Minas Gerais, Rio Grande do Sul e do total da justiça estadual no Brasil em 2010. Considere que o estoque de processos em andamento no estado j (Ej ), no final de 2010, seja um indicador que se define como Ej = Xj + Yj - Zj - Wj , em que j = 1, 2, ..., 27; Xj representa o número de casos novos registrados em 2010 no estado j; Yj seja a quantidade de casos pendentes no estado j (i.e., casos anteriores que não foram solucionados até o final de 2010); Zj denota o total de processos baixados (arquivados) no estado j durante 2010 e Wj seja o número de sentenças e decisões proferidas no estado j até o final de 2010. Considere, por fim, que, para todos os efeitos, o Distrito Federal seja um estado. Com base nessas informações e no quadro acima, julgue os itens que se seguem.
Considerando-se que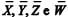 representem, respectivamente, as médias aritméticas das variáveis X, Y, Z e W, então
representem, respectivamente, as médias aritméticas das variáveis X, Y, Z e W, então 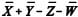 representa a média aritmética da distribuição dos estoques de processos observados nos tribunais estaduais.
representa a média aritmética da distribuição dos estoques de processos observados nos tribunais estaduais.
Considerando-se que
representem, respectivamente, as médias aritméticas das variáveis X, Y, Z e W, então representa a média aritmética da distribuição dos estoques de processos observados nos tribunais estaduais.
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410717
Estatística
O quadro acima mostra uma síntese da movimentação processual dos tribunais de justiça dos estados de São Paulo, Rio de Janeiro, Minas Gerais, Rio Grande do Sul e do total da justiça estadual no Brasil em 2010. Considere que o estoque de processos em andamento no estado j (Ej ), no final de 2010, seja um indicador que se define como Ej = Xj + Yj - Zj - Wj , em que j = 1, 2, ..., 27; Xj representa o número de casos novos registrados em 2010 no estado j; Yj seja a quantidade de casos pendentes no estado j (i.e., casos anteriores que não foram solucionados até o final de 2010); Zj denota o total de processos baixados (arquivados) no estado j durante 2010 e Wj seja o número de sentenças e decisões proferidas no estado j até o final de 2010. Considere, por fim, que, para todos os efeitos, o Distrito Federal seja um estado. Com base nessas informações e no quadro acima, julgue os itens que se seguem.
O quadro apresentado é uma tabela de contingência que mostra o cruzamento entre uma variável qualitativa nominal com 4 níveis de resposta (estados) e outra variável qualitativa com quatro níveis de resposta (casos novos, pendentes, baixados e resolvidos).
O quadro apresentado é uma tabela de contingência que mostra o cruzamento entre uma variável qualitativa nominal com 4 níveis de resposta (estados) e outra variável qualitativa com quatro níveis de resposta (casos novos, pendentes, baixados e resolvidos).
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410716
Estatística
O quadro acima mostra uma síntese da movimentação processual dos tribunais de justiça dos estados de São Paulo, Rio de Janeiro, Minas Gerais, Rio Grande do Sul e do total da justiça estadual no Brasil em 2010. Considere que o estoque de processos em andamento no estado j (Ej ), no final de 2010, seja um indicador que se define como Ej = Xj + Yj - Zj - Wj , em que j = 1, 2, ..., 27; Xj representa o número de casos novos registrados em 2010 no estado j; Yj seja a quantidade de casos pendentes no estado j (i.e., casos anteriores que não foram solucionados até o final de 2010); Zj denota o total de processos baixados (arquivados) no estado j durante 2010 e Wj seja o número de sentenças e decisões proferidas no estado j até o final de 2010. Considere, por fim, que, para todos os efeitos, o Distrito Federal seja um estado. Com base nessas informações e no quadro acima, julgue os itens que se seguem.
Considerando-se apenas os dados relativos aos estados de São Paulo, Rio de Janeiro, Minas Gerais e Rio Grande do Sul quanto à dispersão entre duas variáveis, é correto afirmar que a covariância entre Z e W é superior a 1 e inferior a 2.
Considerando-se apenas os dados relativos aos estados de São Paulo, Rio de Janeiro, Minas Gerais e Rio Grande do Sul quanto à dispersão entre duas variáveis, é correto afirmar que a covariância entre Z e W é superior a 1 e inferior a 2.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409155
Estatística
Considere-se o modelo de séries temporais em tempo discreto na forma Xt = Xt – 1 + f Wt – 1 + Wt , em que t representa o tempo, φ = 1, 2, 3,...; φ … 0 é o coeficiente do modelo e Wt representa um processo de choques aleatórios com média zero e variância σ2 . Com base nessas informações, julgue o item seguinte , acerca da primeira diferença Xt - X t-1.
A função de densidade espectral dessa diferença é h(ω) = σ2( 1 - 2 sen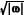 ) / 2π, em que - π ≤ ω ≤ π.
) / 2π, em que - π ≤ ω ≤ π.
A função de densidade espectral dessa diferença é h(ω) = σ2( 1 - 2 sen
) / 2π, em que - π ≤ ω ≤ π.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409154
Estatística
Considere-se o modelo de séries temporais em tempo discreto na forma Xt = Xt – 1 + f Wt – 1 + Wt , em que t representa o tempo, φ = 1, 2, 3,...; φ … 0 é o coeficiente do modelo e Wt representa um processo de choques aleatórios com média zero e variância σ2 . Com base nessas informações, julgue o item seguinte , acerca da primeira diferença Xt - X t-1.
A auto-correlação e a auto-correlação parcial entre Xt - X t - 1 e X t + 12 - X t + 11 são, respectivamente, iguais a φ / 1 + φ2 e ( 1 + φ)12 / 1 + φ2 + φ4 + φ6 +... + φ24
A auto-correlação e a auto-correlação parcial entre Xt - X t - 1 e X t + 12 - X t + 11 são, respectivamente, iguais a φ / 1 + φ2 e ( 1 + φ)12 / 1 + φ2 + φ4 + φ6 +... + φ24
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409153
Estatística
Considere-se o modelo de séries temporais em tempo discreto na forma Xt = Xt – 1 + f Wt – 1 + Wt , em que t representa o tempo, φ = 1, 2, 3,...; φ …0 é o coeficiente do modelo e Wt representa um processo de choques aleatórios com média zero e variância σ2 . Com base nessas informações, julgue o item seguinte , acerca da primeira diferença Xt - X t-1.
Essa diferença é uma série temporal fracamente estacionária.
Essa diferença é uma série temporal fracamente estacionária.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409152
Estatística
Texto associado
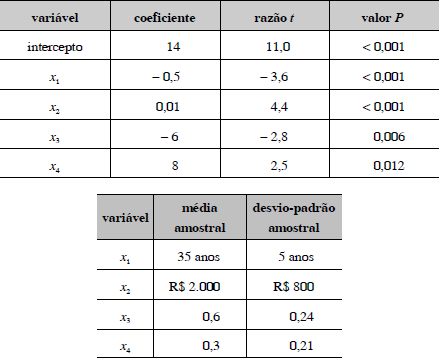
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
O stepwise é um método computacional para a estimação de coeficientes do modelo de regressão linear. Nesse método, inicialmente, todas as q variáveis explanatórias de interesse estão disponíveis no banco de dados. Em seguida, observam-se os valores da razão t e exclui-se aquela variável que possui o maior valor P. Repete-se o procedimento para as q - 1 variáveis restantes e assim sucessivamente. O processo termina quando todas as estimativas dos coeficientes apresentam valores P baixos, como os que estão apresentados no quadro do texto
O stepwise é um método computacional para a estimação de coeficientes do modelo de regressão linear. Nesse método, inicialmente, todas as q variáveis explanatórias de interesse estão disponíveis no banco de dados. Em seguida, observam-se os valores da razão t e exclui-se aquela variável que possui o maior valor P. Repete-se o procedimento para as q - 1 variáveis restantes e assim sucessivamente. O processo termina quando todas as estimativas dos coeficientes apresentam valores P baixos, como os que estão apresentados no quadro do texto
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409151
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
A quantidade de mulheres com x3 = 1 e x4 = 1 é superior a 310.
A quantidade de mulheres com x3 = 1 e x4 = 1 é superior a 310.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409150
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
O coeficiente de variação de x1 é superior a 1.
O coeficiente de variação de x1 é superior a 1.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409148
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
A variável x4 é relativamente mais importante do que a variável x2 , pois seu coeficiente é 800 vezes maior do que o coeficiente de x2 .
A variável x4 é relativamente mais importante do que a variável x2 , pois seu coeficiente é 800 vezes maior do que o coeficiente de x2 .
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409147
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
O modelo ajustado pode ser usado para calcular os valores previstos para cada indivíduo com base nas suas características x1, x2, x3 e x4. O valor esperado da variável resposta é superior a 15 e inferior a 17.
O modelo ajustado pode ser usado para calcular os valores previstos para cada indivíduo com base nas suas características x1, x2, x3 e x4. O valor esperado da variável resposta é superior a 15 e inferior a 17.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409146
Estatística
Com respeito ao texto anterior, considerando uma amostragem aleatória simples (X1, Y1), (X2, Y2), ...., (Xn, Yn) para a estimação dos parâmetros da distribuição (λ > 0, φ > 0), em que cada vetor aleatório (Xk, Yk) é identicamente distribuído como (T1, T2), k = 1, 2, ..., n, julgue o item subseqüente.
Por se tratar de uma amostra aleatória simples, espera-se que a correlação entre Xk e Yk seja nula.
Por se tratar de uma amostra aleatória simples, espera-se que a correlação entre Xk e Yk seja nula.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409145
Estatística
Com respeito ao texto anterior, considerando uma amostragem aleatória simples (X1, Y1), (X2, Y2), ...., (Xn, Yn) para a estimação dos parâmetros da distribuição (λ > 0, φ > 0), em que cada vetor aleatório (Xk, Yk) é identicamente distribuído como (T1, T2), k = 1, 2, ..., n, julgue o item subseqüente.
Um estimador de mínimos quadrados para λ é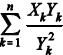
Um estimador de mínimos quadrados para λ é
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409142
Estatística
Texto associado
Considere-se hipoteticamente que o tempo de contribuição previdenciário (T1) e a idade do trabalhador (T2) sejam variáveis aleatórias conjuntamente distribuídas como  , em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
, em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
, em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
Acerca dessa situação hipotética, julgue o item que se segue.
A probabilidade conjunta P(T1 > 0, T2 > 0) é inferior a 0,5.
A probabilidade conjunta P(T1 > 0, T2 > 0) é inferior a 0,5.