Questões de Concurso
Foram encontradas 10.180 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
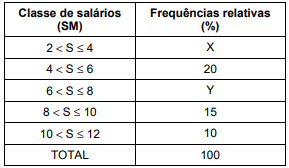
O módulo de (Me – Md) é igual a
I. Nominal: nesse nível podem estar dados qualitativos e quantitativos; eles podem ser organizados pela ordem e pela posição. II. Ordinal: aplica-se apenas a dados qualitativos; nesse nível não são realizados cálculos matemáticos. III. Intervalar: os dados neste nível podem ser ordenados; há diferenças significativas entre eles e um registro nulo não é interpretado como zero inerente. IV. Racional: esse nível é semelhante ao intervalar, mas com duas diferenças: é possível estabelecer razões entre os dados (um dado pode ser múltiplo do outro), e o registro nulo é o zero inerente.
Está correto o que se afirma em
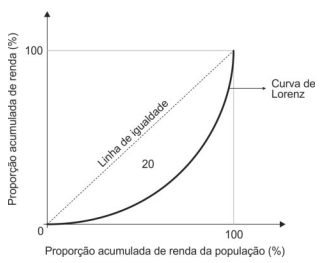
Com base nessas informações, o índice de Gini para a distribuição de renda é
Dados: Log10 3 = 0,48 log10 5 = 0,70 log10 6 = 0,78
− W0 = 0 com probabilidade 1. − Para t > 0, Wt tem distribuição normal com média 0 e variância t. − Para s, t > 0, Wt+s − Ws tem a mesma distribuição de Wt . − Se 0 ≤ q ≤ r ≤ s < t, então Wt − Ws e Wr − Wq são variáveis aleatórias independentes. − A função t ↦ Wt é contínua com probabilidade 1.
Considerando as propriedades apresentadas, a média e a variância de Ws + Wt são, respectivamente,
Se a partícula inicia o passeio na posição 0, a quantidade de passos necessários, em média, para ela retornar à posição 0 é
Atenção: Para responder à questão, considere o código na linguagem R.
Y<-c(2,3,2,4,3,5,6,3,4) #1
X1<-c(10,13,9,18,12,22,27,13,21) #2
X2<-c(6,10,4,10,10,17,16,9,13) #3
dados<-data.frame(cbind(Y,X1,X2)) #4
modelo <- lm(Y ~ X1 + X2, data = dados) #5
summary(modelo) #6
coef(modelo) #7
formula(modelo) #8
plot(modelo) #9
p <- as.data.frame(cbind(13,4)) #10
colnames(p) <- cbind("X1","X2") #11
predict(modelo, newdata=p) #12
vcov(modelo) #13
Intercept<-rep(1,times=9) #14
X<-cbind(Intercept,X1,X2) #15
t(solve(t(X)%*%X)%*%t(X)%*%Y) #16
residuals(modelo) #17
Atenção: Para responder à questão, considere o código na linguagem R.
Y<-c(2,3,2,4,3,5,6,3,4) #1
X1<-c(10,13,9,18,12,22,27,13,21) #2
X2<-c(6,10,4,10,10,17,16,9,13) #3
dados<-data.frame(cbind(Y,X1,X2)) #4
modelo <- lm(Y ~ X1 + X2, data = dados) #5
summary(modelo) #6
coef(modelo) #7
formula(modelo) #8
plot(modelo) #9
p <- as.data.frame(cbind(13,4)) #10
colnames(p) <- cbind("X1","X2") #11
predict(modelo, newdata=p) #12
vcov(modelo) #13
Intercept<-rep(1,times=9) #14
X<-cbind(Intercept,X1,X2) #15
t(solve(t(X)%*%X)%*%t(X)%*%Y) #16
residuals(modelo) #17