Questões de Concurso
Sobre estatística descritiva (análise exploratória de dados) em estatística
Foram encontradas 4.048 questões
Analisando-se os gráficos, foram feitas as informações a seguir.
I - Mais de 50,0% da variação em Y é explicada pela relação linear entre Y e a variável X 2.
II - A relação linear entre Y e a variável X 3 explica 53,2% da variação em Y.
III - A variação de uma unidade em X 3 provoca um aumento de 8,69 unidades em Y.
IV - O coeficiente de correlação linear entre as variáveis Y e X 3 é maior do que entre Y e X 2.
Estão corretas APENAS as afirmações
O Coeficiente de Correlação Linear de Pearson entre os desempenhos de determinados alunos em duas avaliações nacionais é igual a 0,844. Nesse caso, conclui-se que a proporção da variabilidade nos resultados de uma das avaliações explicada pela relação linear entre elas é
As questões de nos 41 a 46 são referentes aos resultados do ENADE 2006, disponíveis em www.inep.gov.br.
Responda às questões de nos 41 a 43 com base nos percentuais das respostas de alunos de uma área específica de determinada Instituição de Ensino Superior (IES), participantes do ENADE 2006, a algumas questões do questionário socioeconômico relativas aos hábitos de leitura.
Uma medida de posição adequada para os dados da questão 24 é a
As questões de nos 41 a 46 são referentes aos resultados do ENADE 2006, disponíveis em www.inep.gov.br.
Responda às questões de nos 41 a 43 com base nos percentuais das respostas de alunos de uma área específica de determinada Instituição de Ensino Superior (IES), participantes do ENADE 2006, a algumas questões do questionário socioeconômico relativas aos hábitos de leitura.
A questão de número 23 do questionário socioeconômico envolve uma variável do tipo
As questões de nos 41 a 46 são referentes aos resultados do ENADE 2006, disponíveis em www.inep.gov.br.
Responda às questões de nos 41 a 43 com base nos percentuais das respostas de alunos de uma área específica de determinada Instituição de Ensino Superior (IES), participantes do ENADE 2006, a algumas questões do questionário socioeconômico relativas aos hábitos de leitura.
Com base nesses resultados, são feitas as afirmativas a seguir.
I - Os alunos dessa IES, proporcionalmente, leram mais livros do que os demais alunos do mesmo curso no país.
II - A maioria dos alunos dessa área nessa IES tem o hábito de ler todos os assuntos dos jornais.
III - Os resultados observados na questão 24 podem ser representados graficamente por um histograma.
IV- Mais da metade dos alunos da região em que se encontra a IES leram, pelo menos, três livros no presente ano.
V - Os alunos dessa IES lêem menos livros técnicos do que os demais alunos da mesma área no estado da IES.
São corretas APENAS as afirmações
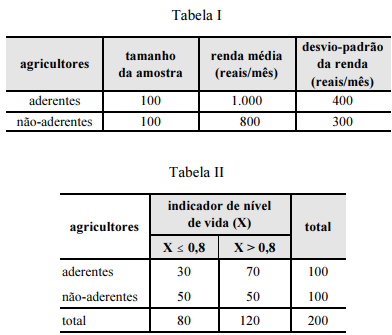
O terceiro quartil da distribuição do indicador X entre os agricultores aderentes ao PRONAF observados na amostra é superior a 0,80.
Considerando-se que não há valores atípicos (ou outliers, ou pontos influentes, ou pontos de alavanca), a correlação entre a renda média mensal e o indicador X é positiva.
A tabela II é uma tabela de contingência que apresenta o cruzamento entre uma variável qualitativa e uma variável quantitativa agrupada em intervalos de classe.
Se a população B for o dobro da população A, então a estimativa da renda média por mês da população formada pela união de ambas as populações será superior a R$ 860,00 e inferior a R$ 890,00.
A tabela I apresenta a distribuição de freqüências para as rendas mensais dos 100 agricultores aderentes e dos 100 agricultores não-aderentes ao PRONAF.
O coeficiente de variação da distribuição da renda entre os aderentes é inferior ao coeficiente de variação da distribuição da renda entre os não-aderentes.
O percentual de réus primários na amostra tem distribuição Normal.
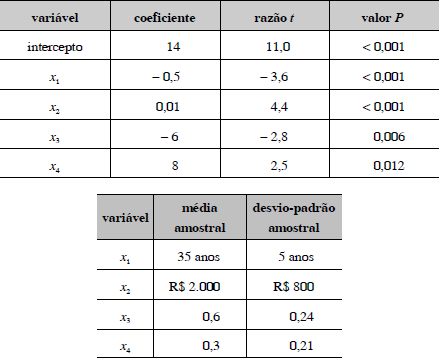
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
O stepwise é um método computacional para a estimação de coeficientes do modelo de regressão linear. Nesse método, inicialmente, todas as q variáveis explanatórias de interesse estão disponíveis no banco de dados. Em seguida, observam-se os valores da razão t e exclui-se aquela variável que possui o maior valor P. Repete-se o procedimento para as q - 1 variáveis restantes e assim sucessivamente. O processo termina quando todas as estimativas dos coeficientes apresentam valores P baixos, como os que estão apresentados no quadro do texto
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
A quantidade de mulheres com x3 = 1 e x4 = 1 é superior a 310.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
O coeficiente de variação de x1 é superior a 1.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
As variáveis dependentes são multicolineares.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
A variável x4 é relativamente mais importante do que a variável x2 , pois seu coeficiente é 800 vezes maior do que o coeficiente de x2 .
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
O modelo ajustado pode ser usado para calcular os valores previstos para cada indivíduo com base nas suas características x1, x2, x3 e x4. O valor esperado da variável resposta é superior a 15 e inferior a 17.