Questões de Concurso
Sobre propriedades dos estimadores em estatística
Foram encontradas 166 questões
Para uma amostra de tamanho n = 20, tem-se coletadas as informações de duas variáveis Y e X com as seguintes informações:
Assumindo que existe uma relação linear entre tais variáveis, o coeficiente angular da reta de regressão de mínimos quadrados será igual a
O valor estimado da média amostral será
Um instituto goiano de pesquisa de opinião deseja estimar o número de pessoas em um município do estado, no ano de 2018, que sofreram algum tipo de acidente de trabalho nos últimos seis meses. Uma pesquisa anterior realizada no ano de 2017 mostrou que 10% dos entrevistados sofreram algum tipo de acidente de trabalho. Qual será o número mínimo de pessoas que deverão ser entrevistadas nesta nova pesquisa, considerando um erro de estimação de 3% e um nível de 95% de confiança?
Um médico trabalha em um município com população de 1000 pessoas e está interessado em implantar um teste diagnóstico para uma doença cuja prevalência é 0,5% na comunidade. A sensibilidade do teste é 100% e a especificidade, 80%. Com a implantação desse teste, é esperado que um acerto diagnóstico (verdadeiro-positivo) seja acompanhado de resultados falso-positivos na razão de, aproximadamente:
Com a finalidade de estimar a proporção p de indivíduos de certa
população, com determinado atributo, através da proporção
amostral 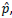 é extraída uma amostra de tamanho n, grande,
compatível com um erro amostral de ɛ e com um grau de
confiança de (1-α). Assim, é correto afirmar que:
é extraída uma amostra de tamanho n, grande,
compatível com um erro amostral de ɛ e com um grau de
confiança de (1-α). Assim, é correto afirmar que:
Seja a amostra aleatória de tamanho n, [x1, x2, x3, ... , xn ], tomada de uma distribuição de Poisson com parâmetro θ, na busca do Estimador de Verossimilhança desse parâmetro θ, o logaritmo da Função de Verossimilhança é
O erro médio quadrático é uma medida do desempenho de um estimador de um parâmetro θ ou de uma função desse parâmetro, q(θ). A definição do erro médio quadrático é R(θ ,T) = E[T(x) - q(θ)]2 , onde T(x) é o estimador de q(θ). Então, é possível afirmar que
Um produto eletrônico tem o seu tempo de garantia modelado por uma distribuição Exponencial. Uma amostra com tamanho n = 100 itens do produto, obtida da assistência técnica, forneceu média amostral de 3,505 anos. A direção da empresa deseja saber qual é o percentual de itens que receberiam manutenção por falha após a entrega do produto se fosse concedida uma garantia de 48 meses. O estatístico da empresa fez os cálculos e afirma que o percentual de itens sujeitos à manutenção é de
Seja o modelo de regressão linear , em que Y é o vetor das respostas (variável dependente) de
dimensão n, X é matriz do modelo de ordem n x p,
é o vetor de parâmetros de dimensão p e
é o vetor
dos erros de dimensão n. Então, admitindo que os erros são i.i.d. com distribuição Normal (Gaussiana)
com média zero e variância σ2, o estimador de mínimos quadrados ordinários do vetor de parâmetros
e o pivô usado para testar a hipótese nula H0i: βi = 0 i = 0, 1, 2, ..... p-1 são, respectivamente,
Existem duas versões para o teste “t” de Student aplicado a dois grupos, a versão clássica e a versão de Aspin-Welch. Geralmente, toma-se uma amostra de tamanho n1 do primeiro grupo e outra de tamanho n2 do segundo grupo. A seguir calculam-se as médias amostrais, os desvios padrões amostrais e a estatística do teste. Para decidir a versão do teste a ser aplicada, o correto é
Existem duas versões para o teste “t” de Student que pode ser aplicado a dois grupos, a versão clássica e a versão de Aspin-Welch. Geralmente, toma-se uma amostra de tamanho n1 do primeiro grupo e outra de tamanho n2 do segundo grupo. A seguir calculam-se as médias amostrais, os desvios padrões amostrais e a estatística do teste. Uma diferença entre as duas versões é
Seja X1, X2, ..., Xn uma amostra aleatória independente e identicamente distribuída de uma U(0, θ) onde X(n) = max(X1, X2, ..., Xn). Qual o estimador não viciado para o parâmetro θ?
Em um modelo de regressão linear múltipla com k variáveis independentes x1, x2, ..., xk e n observações y1, y2, ..., yn solução de mínimos quadrados para estimar o vetor de parâmetros é:
Para responder às questões 46, 47 e 48 use as informações a seguir sobre as variáveis Z e W. Suponha que as duas variáveis estejam relacionadas segundo um modelo de regressão linear simples, Z = β0 + β1 w + ε, sendo ε o termo aleatório e que:
Qual opção informa a estimativa não viciada para a variância?