Questões de Banco de Dados - Big Data para Concurso
Foram encontradas 238 questões
Nas aplicações Big Data, a arquitetura paralela e distribuída (Cluster) é o meio para a criação de soluções capazes de analisar grandes bases de dados, processar seus pesados cálculos e disponibilizar serviços especializados para os mais diversos cenários.
Acerca de Big Data, business intelligence e machine learning julgue o item a seguir.
Big Data se refere a grandes e complexos conjuntos de
dados, que podem estar alocados em múltiplos servidores, e
não necessariamente esses dados precisam estar estruturados.
Acerca de Big Data, business intelligence e machine learning julgue o item a seguir.
O Hadoop MapReduce possui diversas bibliotecas para
manipulação e serialização de arquivos e pode ser utilizado
para disponibilizar integrações de interface para outros
sistemas.
As ferramentas utilizadas para manipular dados em Big Data são as mesmas utilizadas em bancos de dados relacionais.
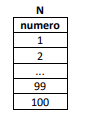
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Big Data pode ser definido como um grande data warehouse, com processos de business intelligence atuando em múltiplos data sets com terabytes de dados.
Com relação a Big Data, julgue o item a seguir.
Uma das aplicações para Big Data é o stream computing, no
qual são processados os dados de mídias sociais e de
streaming de vídeo.
Considerando essa situação hipotética, julgue o item a seguir.
Uma das etapas que a referida área especializada em dados precisará desenvolver é a de análise exploratória, que consiste em pesquisar formas de criptografar os dados em big data da Internet e em inteligências artificiais abertas.
Acerca de armazenamento e processamento de dados, julgue o item a seguir.
Big data é um conceito definido exclusivamente pelo volume
de dados utilizados em análises.
O processo de tomada de decisão dos ecossistemas de big data é guiado por dados, empregando-se soluções computacionais baseadas em algoritmos de aprendizado de máquina relativos à aquisição de informação relevante; a inteligência artificial, por sua vez, limita-se a interpretar os textos existentes e dar respostas rápidas ao usuário.
Nesse tipo de ambiente de bancos de dados, a capacidade de minimizar os ruídos dos dados oriundos de múltiplas fontes heterogêneas, identificar o que é irrelevante e redundante, e apoiar a limpeza dos dados, contribuindo para sua qualidade, corresponde à característica Big Data:
Duas dessas tecnologias são os Bancos de Dados orientados a documentos e orientados a colunas, exemplificados, respectivamente, pelos softwares
Coluna 1 1. Aprendizado Supervisionado. 2. Aprendizado Não Supervisionado. 3. Aprendizado Profundo.
Coluna 2 ( ) O algoritmo recebe um conjunto de dados rotulados e aprende comparando a saída do modelo com a saída esperada, reajustando seus parâmetros até chegar em um limiar aceitável e pré-determinado a priori.
( ) Os algoritmos buscam encontrar padrões ou estruturas em conjuntos de dados não rotulados, por exemplo, gerando agrupamentos de dados.
( ) Conjunto de algoritmos que modelam abstrações de alto nível de dados usando grafos com várias camadas de processamento, compostas de várias transformações lineares e não lineares.
( ) Processo de aprendizado baseado em redes neurais com várias camadas (em geral, mais de cinco camadas): entrada, saída e oculta.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Esse profissional está realizando a seguinte tarefa:
Uma técnica indicada, nesse caso, é a
Além do grande volume de dados, o Big Data, em sua definição original, considera também a(s) seguinte(s) propriedade(s):