Questões de Concurso Público MPE-SC 2022 para Analista de Dados e Pesquisa
Foram encontradas 80 questões
Q1933583
Estatística
Uma empresa recebeu um lote muito grande, milhões de peças
de refugo, e deseja saber quantas peças deverá examinar para
estimar a proporção de itens defeituosos, de modo que o erro de
estimação seja no máximo 2%. Será empregada uma seleção
aleatória de itens onde cada um será classificado como
defeituoso ou não defeituoso. Deseja-se extrair uma amostra
aleatória de tamanho n.
Tendo como padrão um grau de confiança de 95%, o tamanho da amostra necessário para garantir o processo é:
Tendo como padrão um grau de confiança de 95%, o tamanho da amostra necessário para garantir o processo é:
Q1933584
Estatística
Uma prefeitura recebeu uma denúncia de que o número de
autuações feitas pela equipe de fiscalização variava conforme o
dia da semana. Para verificar a procedência da denúncia, as
autuações foram agregadas por dia de semana, como mostra a
tabela a seguir.
Segundas 6 Terças 12 Quartas 9 Quintas 8 Sextas 15 Sábados 13 Domingos 7
Realizando um teste estatístico adequado para verificar se essas autuações ocorrem com a mesma frequência, teremos:
Segundas 6 Terças 12 Quartas 9 Quintas 8 Sextas 15 Sábados 13 Domingos 7
Realizando um teste estatístico adequado para verificar se essas autuações ocorrem com a mesma frequência, teremos:
Q1933585
Estatística
Em um trabalho de pesquisa, as idades das pessoas são: 23, 27,
32, 33, 34, 35, 36, 38, 42, 56 e 58. Deseja-se construir um boxplot
similar ao gráfico a seguir.
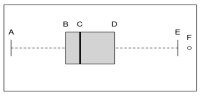
No boxplot acima, os valores das estatísticas nas posições indicadas pelas letras A, B, C, D, E e F são:
No boxplot acima, os valores das estatísticas nas posições indicadas pelas letras A, B, C, D, E e F são:
Q1933586
Estatística
Uma biblioteca está classificando os seus frequentadores em
grupos literários para facilitar a aquisição e a organização dos
livros. Isso foi feito aplicando o algoritmo KNN ao banco de dados
de usuários da biblioteca, incluindo alguns dos campos de
informação como atributos, tais como idade e nível de formação
acadêmica. Em um experimento, uma segunda classificação foi
feita usando um conjunto maior de atributos, incluindo ambos de
maior ou menor relevância percebida com relação aos grupos
definidos.
A segunda classificação tende a ser:
A segunda classificação tende a ser:
Q1933587
Banco de Dados
O método random forests para classificação ou regressão
potencializa alguns benefícios das árvores de decisão e por isso é
preferido em certas situações.
O uso de random forests seria vantajoso em relação à árvore de decisão no seguinte caso:
O uso de random forests seria vantajoso em relação à árvore de decisão no seguinte caso:
Q1933588
Estatística
A aplicação do algoritmo AdaBoost, utilizando classificadores
SVM, permitiu a obtenção de um modelo classificador de sinais
sonoros com excelente precisão. Entretanto, esse modelo possui
requisitos computacionais além da capacidade da plataforma
onde se deseja aplicá-lo.
Considerando o problema acima descrito, a técnica a ser utilizada para contornar o problema é:
Considerando o problema acima descrito, a técnica a ser utilizada para contornar o problema é:
Q1933589
Estatística
Para realizar o agrupamento de um conjunto de 4 observações
(A, B, C e D) foi decidido usar o método de agrupamento
hierárquico aglomerativo com ligação simples (single-linkage).
A matriz de distância inicial entre os elementos é apresentada a seguir.
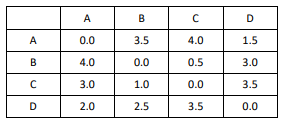
Considerando essas informações, a matriz de distância obtida após o primeiro passo do agrupamento é:
A matriz de distância inicial entre os elementos é apresentada a seguir.
Considerando essas informações, a matriz de distância obtida após o primeiro passo do agrupamento é:
Q1933590
Estatística
A atividade de classificação de documentos envolve um grande
número de tarefas de processamento de linguagem natural, o
que pode levar a dúvidas quanto a sua aplicação.
A alternativa que contém apenas tarefas que sejam exemplos de classificação de documentos é:
A alternativa que contém apenas tarefas que sejam exemplos de classificação de documentos é:
Q1933591
Estatística
Um modelo semântico vetorial foi criado com a seguinte
definição:
v(w)i = tf(w, di) ∙ idf(w, D)
onde v é o vetor correspondente à palavra w, di é o i-ésimo documento da coleção D de artigos da Wikipédia, ordenados alfabeticamente por título, e tf e idf são, respectivamente, as funções de frequência de termo e inverso da frequência em documentos.
A alternativa que classifica corretamente o modelo acima descrito e apresenta a razão correta para a classificação é:
v(w)i = tf(w, di) ∙ idf(w, D)
onde v é o vetor correspondente à palavra w, di é o i-ésimo documento da coleção D de artigos da Wikipédia, ordenados alfabeticamente por título, e tf e idf são, respectivamente, as funções de frequência de termo e inverso da frequência em documentos.
A alternativa que classifica corretamente o modelo acima descrito e apresenta a razão correta para a classificação é:
Q1933592
Estatística
O método Latent Dirichlet Allocation (LDA) é popularmente
utilizado para a construção de modelos de tópicos devido a sua
flexibilidade e robustez, particularmente em grandes quantidades
de texto. Ao mencionar a escolha do LDA em um projeto, um
analista foi questionado sobre que aspectos caracterizam a
flexibilidade do modelo, especialmente em comparação a um
modelo pLSA.
O analista respondeu corretamente:
O analista respondeu corretamente:
Q1933593
Estatística
Um problema comum no processamento de texto é o tratamento
de termos compostos por mais de um token, tais como
“Ministério Público”, tal que represente uma unidade linguística
distinta, em particular na construção de modelos de linguagem.
Considerando o problema acima descrito, a alternativa que apresenta uma técnica usada para sua resolução é:
Considerando o problema acima descrito, a alternativa que apresenta uma técnica usada para sua resolução é:
Q1933594
Estatística
No contexto da linguagem de programação R, analise o código a
seguir.
for (x in 1:10) { if (x >= 4) { print(x) next } if (x == 8) {break} }
O número de linhas exibidas pela execução desse código é:
for (x in 1:10) { if (x >= 4) { print(x) next } if (x == 8) {break} }
O número de linhas exibidas pela execução desse código é:
Q1933595
Programação
Analise o código da linguagem de programação R a seguir.
xpto <- array(c(1:24), dim = c(4, 3, 2)) print (xpto[3, 2, 1])
Na execução desse código, o print produz o valor:
xpto <- array(c(1:24), dim = c(4, 3, 2)) print (xpto[3, 2, 1])
Na execução desse código, o print produz o valor:
Q1933596
Estatística
No contexto da linguagem de programação R, analise as
afirmativas a seguir.
I. Vetores (vectors) são listas de itens que devem ter o mesmo tipo.
II. R trabalha com vários tipos de dados (data types), numéricos, lógicos e textuais, mas as variáveis podem mudar de tipo mesmo depois da instanciação.
III. Os itens de uma lista (list) não podem ser substituídos. São permitidas apenas a inserção e a remoção de itens.
Está correto somente o que se afirma em:
I. Vetores (vectors) são listas de itens que devem ter o mesmo tipo.
II. R trabalha com vários tipos de dados (data types), numéricos, lógicos e textuais, mas as variáveis podem mudar de tipo mesmo depois da instanciação.
III. Os itens de uma lista (list) não podem ser substituídos. São permitidas apenas a inserção e a remoção de itens.
Está correto somente o que se afirma em:
Q1933597
Programação
Analise o código Python a seguir.
x1 = {"A", "B", "C"} x2 = ["AA", "BB", "CC"] x1.add("B") x2.append("BB") x2.append(x1) print (x2)
Dado que os elementos de x1 podem ser exibidos em ordem aleatória, a linha que possivelmente é produzida pelo comando print na execução do código acima é:
x1 = {"A", "B", "C"} x2 = ["AA", "BB", "CC"] x1.add("B") x2.append("BB") x2.append(x1) print (x2)
Dado que os elementos de x1 podem ser exibidos em ordem aleatória, a linha que possivelmente é produzida pelo comando print na execução do código acima é:
Q1933598
Programação
Analise o código Python a seguir.
s=0 for k in range(16,10, -2): s -= k print (s)
O valor exibido pela execução desse trecho é:
s=0 for k in range(16,10, -2): s -= k print (s)
O valor exibido pela execução desse trecho é:
Q1933599
Programação
Analise o código Python a seguir.

A saída produzida pela execução desse trecho é:
A saída produzida pela execução desse trecho é:
Q1933600
Banco de Dados
Num banco de dados relacional, considere as tabelas T1 e T2,
criadas como descrito a seguir.
• T1 tem duas colunas, intituladas A e B, do tipo inteiro; a coluna A é declarada como primary key, e não aceita valores nulos.
• T2 tem duas colunas, intituladas C e A, do tipo inteiro; a coluna C é declarada como primary key, e não aceita valores nulos; a coluna A foi declarada como UNIQUE, não aceita valores nulos e ainda foi declarada como uma foreign key que referencia a coluna A da tabela T1.
À luz dessa estrutura, é correto afirmar que o relacionamento entre T1 e T2:
• T1 tem duas colunas, intituladas A e B, do tipo inteiro; a coluna A é declarada como primary key, e não aceita valores nulos.
• T2 tem duas colunas, intituladas C e A, do tipo inteiro; a coluna C é declarada como primary key, e não aceita valores nulos; a coluna A foi declarada como UNIQUE, não aceita valores nulos e ainda foi declarada como uma foreign key que referencia a coluna A da tabela T1.
À luz dessa estrutura, é correto afirmar que o relacionamento entre T1 e T2:
Q1933601
Banco de Dados
A modelagem de bancos de dados passa pela análise das relações
e comportamento dos dados que futuramente constituirão o
conteúdo desses bancos. Para bancos de dados relacionais, essa
modelagem passa pelo levantamento das dependências
funcionais que eventualmente possam ser depreendidas em cada
caso.
Como um exemplo, considere um banco de dados que armazena a data de nascimento, o CPF (Cadastro de Pessoas Físicas) e a CNH (Carteira Nacional de Habilitação) de um grupo de pessoas, no qual todas possuem CPF e CNH.
Dado que no Brasil o CPF e a CNH são individualizados, as dependências funcionais que devem ser consideradas, em conjunto, são:
Como um exemplo, considere um banco de dados que armazena a data de nascimento, o CPF (Cadastro de Pessoas Físicas) e a CNH (Carteira Nacional de Habilitação) de um grupo de pessoas, no qual todas possuem CPF e CNH.
Dado que no Brasil o CPF e a CNH são individualizados, as dependências funcionais que devem ser consideradas, em conjunto, são:
Q1933602
Direito Digital
De acordo com a LGPD (Lei Geral de Proteção de Dados Pessoais),
o consentimento é a manifestação livre, informada e inequívoca
pela qual o titular concorda com o tratamento de seus dados
pessoais para uma finalidade determinada.
Conforme o Art. 8º, §2º, da Lei nº 13.709/2018, o ônus da prova de que o consentimento foi obtido em conformidade com o disposto na LGPD é do(a):
Conforme o Art. 8º, §2º, da Lei nº 13.709/2018, o ônus da prova de que o consentimento foi obtido em conformidade com o disposto na LGPD é do(a):