Questões de Concurso
Para dataprev
Foram encontradas 2.610 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276921
Engenharia de Software
Julgue o próximo item, relativos a aprendizado de máquina.
O aprendizado por reforço é um tipo de aprendizagem de máquina que tem por objetivo prever o resultado de um atributo alvo exclusivamente por meio de reforço no treinamento do modelo.
O aprendizado por reforço é um tipo de aprendizagem de máquina que tem por objetivo prever o resultado de um atributo alvo exclusivamente por meio de reforço no treinamento do modelo.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276920
Engenharia de Software
Julgue o próximo item, relativos a aprendizado de máquina.
A técnica de agrupamento é um tipo de aprendizado não supervisionado em que o algoritmo identifica padrões em um conjunto de dados de entrada sem ter recebido qualquer feedback prévio.
A técnica de agrupamento é um tipo de aprendizado não supervisionado em que o algoritmo identifica padrões em um conjunto de dados de entrada sem ter recebido qualquer feedback prévio.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276919
Engenharia de Software
Julgue o próximo item, relativos a aprendizado de máquina.
Os algoritmos SVM (support vector machines) realizam apenas tarefas de regressão.
Os algoritmos SVM (support vector machines) realizam apenas tarefas de regressão.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276918
Engenharia de Software
Julgue o próximo item, relativos a aprendizado de máquina.
As técnicas de regressão utilizam um conjunto finito de
hipóteses para, a partir dos atributos previsores, determinar a
categoria de um objeto do conjunto de dados analisado.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276916
Engenharia de Software
No que se refere a técnicas, ferramentas e algoritmos de aprendizado não supervisionado, julgue o item a seguir.
O algoritmo k-means seleciona objetos reais de uma base de dados como centroide do grupo para realizar o agrupamento de objetos semelhantes.
O algoritmo k-means seleciona objetos reais de uma base de dados como centroide do grupo para realizar o agrupamento de objetos semelhantes.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276915
Engenharia de Software
No que se refere a técnicas, ferramentas e algoritmos de aprendizado não supervisionado, julgue o item a seguir.
O PCA é um procedimento estatístico que converte um conjunto de objetos com atributos possivelmente correlacionados em um conjunto de objetos com atributos linearmente descorrelacionados.
O PCA é um procedimento estatístico que converte um conjunto de objetos com atributos possivelmente correlacionados em um conjunto de objetos com atributos linearmente descorrelacionados.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276914
Engenharia de Software
No que se refere a técnicas, ferramentas e algoritmos de aprendizado não supervisionado, julgue o item a seguir.
A compressão de atributos é uma técnica de redução de dimensionalidade na qual atributos irrelevantes ou redundantes são identificados e desconsiderados.
A compressão de atributos é uma técnica de redução de dimensionalidade na qual atributos irrelevantes ou redundantes são identificados e desconsiderados.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276913
Engenharia de Software
No que se refere a técnicas, ferramentas e algoritmos de aprendizado não supervisionado, julgue o item a seguir.
A regra de associação é uma técnica que busca relações de co-ocorrência entre objetos de uma base de dados.
A regra de associação é uma técnica que busca relações de co-ocorrência entre objetos de uma base de dados.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276911
Programação
A respeito das bibliotecas NumPy e Pandas, julgue o item a seguir.
A biblioteca numpy permite realizar operações matemáticas entre arrays de diferentes dimensões usando o mecanismo de broadcast.
A biblioteca numpy permite realizar operações matemáticas entre arrays de diferentes dimensões usando o mecanismo de broadcast.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276910
Programação
A respeito das bibliotecas NumPy e Pandas, julgue o item a seguir.
O método describe() da biblioteca Pandas retorna as linhas superiores e inferiores do DataFrame.
O método describe() da biblioteca Pandas retorna as linhas superiores e inferiores do DataFrame.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276909
Programação
A respeito das bibliotecas NumPy e Pandas, julgue o item a seguir.
A biblioteca Pandas apresenta os dados em uma estrutura de DataFrame, composta por linhas e colunas.
A biblioteca Pandas apresenta os dados em uma estrutura de DataFrame, composta por linhas e colunas.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276908
Programação
A respeito das bibliotecas NumPy e Pandas, julgue o item a seguir.
Se um conjunto de dados for armazenado em um array numpy, então, por meio dos seus métodos pré-definidos, será possível obter dados de resumo estatístico desse conjunto de dados.
Se um conjunto de dados for armazenado em um array numpy, então, por meio dos seus métodos pré-definidos, será possível obter dados de resumo estatístico desse conjunto de dados.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276907
Programação
A respeito das bibliotecas NumPy e Pandas, julgue o item a seguir.
A classe numpy.poly1d() permite a criação de arrays
multidimensionais.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276906
Estatística
Uma amostra aleatória simples de tamanho n = 4, denotada por X1, X2 , X3, X4, foi retirada de uma população cuja função de distribuição de probabilidade é representada pela expressão P (X = x) = πx (1 − π)1-x , na qual x pode assumir os valores 0 ou 1 e π é o parâmetro desconhecido que denota uma probabilidade.
A partir das informações anteriores, e considerando a estimação do parâmetro π e o teste da hipótese nula H0: π = 0,5 contra a hipótese alternativa H1: π ≠ 0,5, bem como sabendo que os valores observados na amostra foram 0,0,0,1, julgue o item a seguir.
Mantendo-se os mesmos valores 0,0,0,1 observados na amostra, o intervalo simétrico de 95% de confiança para π deve apresentar amplitude superior àquela proporcionada pelo intervalo simétrico de 99% de confiança para esse mesmo parâmetro.
A partir das informações anteriores, e considerando a estimação do parâmetro π e o teste da hipótese nula H0: π = 0,5 contra a hipótese alternativa H1: π ≠ 0,5, bem como sabendo que os valores observados na amostra foram 0,0,0,1, julgue o item a seguir.
Mantendo-se os mesmos valores 0,0,0,1 observados na amostra, o intervalo simétrico de 95% de confiança para π deve apresentar amplitude superior àquela proporcionada pelo intervalo simétrico de 99% de confiança para esse mesmo parâmetro.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276905
Estatística
Uma amostra aleatória simples de tamanho n = 4, denotada por X1, X2 , X3, X4, foi retirada de uma população cuja função de distribuição de probabilidade é representada pela expressão P (X = x) = πx (1 − π)1-x , na qual x pode assumir os valores 0 ou 1 e π é o parâmetro desconhecido que denota uma probabilidade.
A partir das informações anteriores, e considerando a estimação do parâmetro π e o teste da hipótese nula H0: π = 0,5 contra a hipótese alternativa H1: π ≠ 0,5, bem como sabendo que os valores observados na amostra foram 0,0,0,1, julgue o item a seguir.
Sob a hipótese nula, a variância populacional é igual a 0,25.
A partir das informações anteriores, e considerando a estimação do parâmetro π e o teste da hipótese nula H0: π = 0,5 contra a hipótese alternativa H1: π ≠ 0,5, bem como sabendo que os valores observados na amostra foram 0,0,0,1, julgue o item a seguir.
Sob a hipótese nula, a variância populacional é igual a 0,25.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276904
Estatística
Uma amostra aleatória simples de tamanho n = 4,
denotada por X1, X2 , X3, X4, foi retirada de uma população cuja
função de distribuição de probabilidade é representada pela
expressão P (X = x) = πx (1 − π)1-x , na qual x pode assumir os
valores 0 ou 1 e π é o parâmetro desconhecido que denota uma
probabilidade.
A partir das informações anteriores, e considerando a estimação do parâmetro π e o teste da hipótese nula H0: π = 0,5 contra a hipótese alternativa H1: π ≠ 0,5, bem como sabendo que os valores observados na amostra foram 0,0,0,1, julgue o item a seguir.
A estimativa de máxima verossimilhança da probabilidade π é igual a 0,75.
A partir das informações anteriores, e considerando a estimação do parâmetro π e o teste da hipótese nula H0: π = 0,5 contra a hipótese alternativa H1: π ≠ 0,5, bem como sabendo que os valores observados na amostra foram 0,0,0,1, julgue o item a seguir.
A estimativa de máxima verossimilhança da probabilidade π é igual a 0,75.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276903
Estatística
No que se refere à variável aleatória V, que segue uma distribuição contínua, tal que P ( V > v) = exp (−v), se v ≥ 0, e P ( V > v) = 0, se v < 0, julgue o próximo item.
P (V = 0) = exp (0).
P (V = 0) = exp (0).
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276902
Estatística
No que se refere à variável aleatória V, que segue uma distribuição contínua, tal que P ( V > v) = exp (−v), se v ≥ 0, e P ( V > v) = 0, se v < 0, julgue o próximo item.
A esperança e a variância de V são iguais a 1.
A esperança e a variância de V são iguais a 1.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276901
Estatística
No que se refere à variável aleatória V, que segue uma distribuição contínua, tal que P ( V > v) = exp (−v), se v ≥ 0, e P ( V > v) = 0, se v < 0, julgue o próximo item.
P ( V > 1|V > 2) = 1.
Ano: 2023
Banca:
CESPE / CEBRASPE
Órgão:
DATAPREV
Prova:
CESPE / CEBRASPE - 2023 - DATAPREV - Analista de Tecnologia da Informação - Perfil: Inteligência da informação |
Q2276900
Estatística
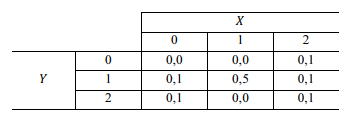
Considerando o quadro precedente, que mostra a distribuição conjunta de um par de variáveis aleatórias discretas (X, Y), julgue o seguinte item.
As variáveis X e Y possuem a mesma esperança.
As variáveis X e Y possuem a mesma esperança.