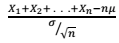Questões de Concurso
Sobre amostragem em estatística
Foram encontradas 1.212 questões
Considere o modelo de regressão linear múltipla com intercepto, da variável dependente Y sobre as p variáveis independentes (X1 , X2 , ..., Xp ), na forma matricial:
E(Y) = X.β
Utilizando uma amostra de tamanho n, obtemos o estimador
dos mínimos quadrados ordinários  =(XTX)-1
XTY. Os
valores estimados de Y,
=(XTX)-1
XTY. Os
valores estimados de Y, 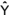 =X
=X , podem ser expressos por
meio de
, podem ser expressos por
meio de 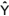 = X.(XTX)-1
XTY.
= X.(XTX)-1
XTY.
Fazendo H = X.(XTX)-1
XT, tem-se 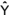 =H.Y, sendo a matriz
n x n, H, denominada matriz de projeção, isto é, a matriz
que projeta o vetor das observações amostrais, Y, no espaço
dos valores estimados
=H.Y, sendo a matriz
n x n, H, denominada matriz de projeção, isto é, a matriz
que projeta o vetor das observações amostrais, Y, no espaço
dos valores estimados 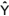 .
.
Diante das considerações feitas acima, observe as afirmações a seguir.:
I - H é uma matriz idempotente.
II -
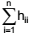 = rank(X) = p , onde hii é o io
elemento da diagonal
da matriz H.
= rank(X) = p , onde hii é o io
elemento da diagonal
da matriz H.
III - H.(I – H) = O, onde I é a matriz identidade e O, a matriz nula.
IV - e = (I – H).Y, onde e é o vetor dos resíduos amostrais.
Está correto o que se afirma em:
Uma amostra aleatória simples de tamanho n foi extraída
de modo independente de uma população com distribuição
normal com parâmetros μ e σ, ambos desconhecidos,
a fim de se estimar a variância, σ2
, da característica de
interesse, Y. O estimador de máxima verossimilhança da amostra foi obtido e expresso por 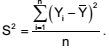
Se 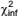 e
e 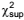 são os limites inferior e superior da distribuição
qui-quadrado com probabilidade (1 – α)100% de
se obter um valor entre eles, então para esse nível de
confiança, uma estimativa não tendenciosa, por intervalo,
para a variância da população é
são os limites inferior e superior da distribuição
qui-quadrado com probabilidade (1 – α)100% de
se obter um valor entre eles, então para esse nível de
confiança, uma estimativa não tendenciosa, por intervalo,
para a variância da população é
Uma amostra aleatória de tamanho n deve ser extraída
de uma população infinita a fim de se estimar a proporção
da população, 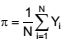 , por meio da estatística
Proporção da Amostra,
, por meio da estatística
Proporção da Amostra, 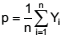 , sendo Yi
uma variável aleatória Bernoulli (π).
, sendo Yi
uma variável aleatória Bernoulli (π).
Na falta de conhecimento prévio da variância do estimador, optou-se por calcular o tamanho da amostra conservador, considerando uma variância máxima, para um nível de confiança de aproximadamente 95%, e um erro amostral absoluto máximo de um ponto percentual.
Com esses parâmetros, o valor mais aproximado para o
tamanho final da amostra é
Uma amostra aleatória de tamanho n > 1 foi extraída independentemente,
sem reposição, de uma população de
tamanho N com distribuição Bernoulli (π ), a fim de se estimar
o total,  , de unidades na população com a característica
A.
, de unidades na população com a característica
A.
Um estimador não tendencioso de  é definido como:
é definido como:
Seja (Y1 , Y2 , Y3 ) uma amostra aleatória simples extraída de modo independente de uma população com média μ e variância σ2 , ambas desconhecidas. Considere os dois estimadores da média da população definidos abaixo:
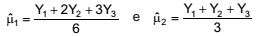
Relativamente a esses dois estimadores, conclui-se que
A respeito de estatística aplicada às ciências sociais, julgue o item que se segue.
Entende-se por amostra representativa um subconjunto de
determinada população que tenha a mesma estrutura ou
composição da população que representa.
Um estudo acerca do tempo (x, em anos) de guarda de
autos findos em determinada seção judiciária considerou uma
amostragem aleatória estratificada. A população consiste de uma
listagem de autos findos, que foi segmentada em quatro estratos,
segundo a classe de cada processo (as classes foram estabelecidas
por resolução de autoridade judiciária). A tabela a seguir mostra os
tamanhos populacionais (N) e amostrais (n), a média amostral
 e a variância amostral dos tempos (s2
) correspondentes a cada
estrato.
e a variância amostral dos tempos (s2
) correspondentes a cada
estrato.

Considerando que o objetivo do estudo seja estimar o tempo médio populacional (em anos) de guarda dos autos findos, julgue o item a seguir.
Combinando-se todos os estratos envolvidos, a estimativa da
variância do tempo médio amostral da guarda dos autos findos
é inferior a 0,005 ano2
.
Um estudo acerca do tempo (x, em anos) de guarda de
autos findos em determinada seção judiciária considerou uma
amostragem aleatória estratificada. A população consiste de uma
listagem de autos findos, que foi segmentada em quatro estratos,
segundo a classe de cada processo (as classes foram estabelecidas
por resolução de autoridade judiciária). A tabela a seguir mostra os
tamanhos populacionais (N) e amostrais (n), a média amostral
e a variância amostral dos tempos (s2
) correspondentes a cada
estrato.
Considerando que o objetivo do estudo seja estimar o tempo médio populacional (em anos) de guarda dos autos findos, julgue o item a seguir.
No estudo em questão foi aplicada uma amostragem aleatória
estratificada com alocação proporcional ao tamanho dos
estratos.
Uma amostra aleatória simples Y1, Y2, ..., Yn, retirada de uma população Bernoulli, é tal que

para y = 0 ou 1, 0 < θ < 1 e k = 1, 2, ..., n. O objetivo é efetuar
inferências acerca do parâmetro θ mediante aplicação de métodos
computacionais.
Considerando que para r ≥ 0, 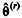 represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
O método HPD (high probability density) é um algoritmo que
proporciona um intervalo de confiança clássico (frequentista)
para o parâmetro θ.
Uma amostra aleatória simples Y1, Y2, ..., Yn, retirada de uma população Bernoulli, é tal que
para y = 0 ou 1, 0 < θ < 1 e k = 1, 2, ..., n. O objetivo é efetuar
inferências acerca do parâmetro θ mediante aplicação de métodos
computacionais.
Considerando que para r ≥ 0, 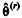 represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
O amostrador de Gibbs, um algoritmo sequencial de Monte
Carlo, permite simular a distribuição a priori do parâmetro θ,
desde que a forma funcional da sua função de densidade, ƒ(θ),
seja conhecida.
Uma amostra aleatória simples Y1, Y2, ..., Yn, retirada de uma população Bernoulli, é tal que
para y = 0 ou 1, 0 < θ < 1 e k = 1, 2, ..., n. O objetivo é efetuar
inferências acerca do parâmetro θ mediante aplicação de métodos
computacionais.
Considerando que para r ≥ 0, 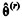 represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
No algoritmo de Metropolis-Hastings tem-se a forma iterativa 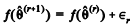 , na qual ƒ representa a função de
densidade a priori de θ, e ∈, > 0 representa um incremento
aleatório. Nesse algoritmo, a probabilidade de aceitação do
valor proposto
, na qual ƒ representa a função de
densidade a priori de θ, e ∈, > 0 representa um incremento
aleatório. Nesse algoritmo, a probabilidade de aceitação do
valor proposto 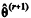 como uma estimativa viável para o
parâmetro de interesse é constante.
como uma estimativa viável para o
parâmetro de interesse é constante.
Uma amostra aleatória simples Y1, Y2, ..., Yn, retirada de uma população Bernoulli, é tal que
para y = 0 ou 1, 0 < θ < 1 e k = 1, 2, ..., n. O objetivo é efetuar
inferências acerca do parâmetro θ mediante aplicação de métodos
computacionais.
Considerando que para r ≥ 0, 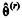 represente a estimativa de θ
obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
represente a estimativa de θ
obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
O método de Monte Carlo via cadeia de Markov (MCMC)
pertence à classe de algoritmos de estimação não sequencial,
em que 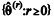 forma um conjunto de valores mutuamente
independentes. Excluindo-se o valor inicial
forma um conjunto de valores mutuamente
independentes. Excluindo-se o valor inicial 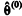 , uma
estimativa do parâmetro θ é dada por
, uma
estimativa do parâmetro θ é dada por 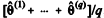 , na
qual q representa um valor suficientemente grande.
, na
qual q representa um valor suficientemente grande.
A respeito do total amostral Tn = X1 + X2 + ... + Xn, em que X1, X2, ..., Xn é uma amostra aleatória simples retirada de uma distribuição gama com média µ e desvio padrão σ, julgue o próximo item.
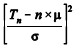 converge quase certamente a uma distribuição
qui-quadrado com 1 grau de liberdade.
converge quase certamente a uma distribuição
qui-quadrado com 1 grau de liberdade. A respeito do total amostral Tn = X1 + X2 + ... + Xn, em que X1, X2, ..., Xn é uma amostra aleatória simples retirada de uma distribuição gama com média µ e desvio padrão σ, julgue o próximo item.
O total amostral Tn segue distribuição gama com desvio padrão n × σ.
A respeito do total amostral Tn = X1 + X2 + ... + Xn, em que X1, X2, ..., Xn é uma amostra aleatória simples retirada de uma distribuição gama com média µ e desvio padrão σ, julgue o próximo item.
O valor esperado do total amostral Tn é igual a µ.
Uma amostra aleatória simples, com reposição, de n observações X1, X2, ... Xn, foi selecionada de uma população com distribuição uniforme contínua no intervalo [−2,b], b > −2.
Sabe-se que:
I. a média dessa distribuição uniforme é igual a 10;
II. o desvio padrão de 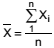 é igual a 0,4.
é igual a 0,4.
Nessas condições, o valor de n é igual a
As técnicas de amostragens são importantes para selecionarmos os elementos que deverão ser pesquisados. Ao decidir trabalhar com amostragem probabilística, julgue as seguintes afirmações.
I. Quanto menor a amplitude do intervalo, maior deve ser o tamanho da amostra.
II. Quanto maior o número de subgrupos de interesse, maior deve ser o tamanho da amostra.
III. Quanto mais alto o nível de significância estabelecido, maior deve ser a amostra.
IV. Quanto maior a dispersão dos dados na população, maior deve ser o tamanho da amostra.
As afirmações I, II, III e IV são, respectivamente:
Quando nos referimos a uma sequência de variáveis aleatórias {Xi} com i ≥ 1, independentes e identicamente distribuídas, com média μ e variância σ2 , sendo estas finitas, podemos afirmar que: