Questões de Concurso
Sobre amostragem em estatística
Foram encontradas 1.212 questões
Julgue o item a seguir, a respeito de amostragem por conglomerados, considerando uma população U = {1, ..., 6} com conglomerados C1 = {1}, C2 = {2, 3} e C3 = {4, 5, 6} e o vetor de dados associado D = (15, 10, 4, 5, 8, 6).
Se dois dos três conglomerados — C1, C2, C3 — da população
U forem escolhidos para formar a amostra, a média amostral
assume os seguintes possíveis valores: 29/3, 17/2 e 33/5, de
modo que cada um desses valores ocorre com a mesma
probabilidade, isto é, 1/3.
Julgue o item a seguir, a respeito de amostragem por conglomerados, considerando uma população U = {1, ..., 6} com conglomerados C1 = {1}, C2 = {2, 3} e C3 = {4, 5, 6} e o vetor de dados associado D = (15, 10, 4, 5, 8, 6).
Se dois dos três conglomerados — C1, C2, C3 — da população
U forem escolhidos em seguida para formar a amostra, as
possíveis amostras serão: {1, 2, 3}, {1, 4, 5, 6}, {2, 3, 1},
{2, 3, 4, 5, 6}, {4, 5, 6, 1}, {4, 5, 6, 1, 2, 3}.
A população de uma cidade divide-se em três estratos: classe baixa (CB), com 25% da população; classe média (CM), com 60%; e classe alta (CA), com 15%. O desvio padrão dos salários mensais das classes é R$ 400,00 R$ 600,00 e R$ 2.800/3, respectivamente. A fim de se estimar o salário mensal médio da população, escolhe-se uma amostra de tamanho n. Com base nessas informações, julgue o item subsequente acerca da amostragem.
Considerando uma amostra estratificada de tamanho n = 600
com alocação ótima de Neyman, é correto afirmar que do
estrato CM devem ser amostradas 360 pessoas.
A população de uma cidade divide-se em três estratos: classe baixa (CB), com 25% da população; classe média (CM), com 60%; e classe alta (CA), com 15%. O desvio padrão dos salários mensais das classes é R$ 400,00 R$ 600,00 e R$ 2.800/3, respectivamente. A fim de se estimar o salário mensal médio da população, escolhe-se uma amostra de tamanho n. Com base nessas informações, julgue o item subsequente acerca da amostragem.
Na amostragem aleatória estratificada com alocação
proporcional aos tamanhos dos estratos, uma amostra de
n = 400 pessoas deve contemplar 60 pessoas da CB, 240 da
CM e 100 da CA.
A população de uma cidade divide-se em três estratos: classe baixa (CB), com 25% da população; classe média (CM), com 60%; e classe alta (CA), com 15%. O desvio padrão dos salários mensais das classes é R$ 400,00 R$ 600,00 e R$ 2.800/3, respectivamente. A fim de se estimar o salário mensal médio da população, escolhe-se uma amostra de tamanho n. Com base nessas informações, julgue o item subsequente acerca da amostragem.
A probabilidade de que uma amostra aleatória simples de
tamanho n = 10 não contenha pessoas da CB é superior a
0,1%.

A tabela acima mostra os resultados de um estudo demográfico em que se analisou o crescimento da população de determinada cidade ao longo do tempo. Considerando os dados da tabela e uma curva de crescimento exponencial y = ε α eβt , em que e representa um erro aleatório com média unitária, julgue o item subsequente.
É correto linearizar o modelo com a reparametrização a = ln α e a transformação da variável dependente z = ln y. Dessa forma resulta o modelo z = a + βt + ln ε.
A tabela acima mostra os resultados de um estudo demográfico em que se analisou o crescimento da população de determinada cidade ao longo do tempo. Considerando os dados da tabela e uma curva de crescimento exponencial y = ε α eβt , em que e representa um erro aleatório com média unitária, julgue o item subsequente.
Calculando-se as derivadas parciais Sα e Sβ da soma dos erros quadrados, as equações Sα = 0 e Sβ = 0 fornecem as seguintes equações normais:
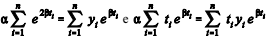
Uma amostra aleatória simples X1, X2, ..., Xn foi retirada de uma distribuição contínua, em que θ é o parâmetro de interesse e Sn = S(X1, X2, ..., Xn) é o seu estimador. A respeito dessa amostra, julgue o próximo item.
Se Sn e θ forem as médias amostral e populacional,
respectivamente, então — conforme a lei fraca dos grandes
números — Sn converge quase certamente para θ, à medida que
n cresce.
Uma amostra aleatória simples X1, X2, ..., Xn foi retirada de uma distribuição contínua, em que θ é o parâmetro de interesse e Sn = S(X1, X2, ..., Xn) é o seu estimador. A respeito dessa amostra, julgue o próximo item.
Se o estimador Sn converge em norma L1 para o parâmetro θ à
medida que o tamanho da amostra aumenta, então Sn converge
em probabilidade para θ.
A distribuição conjunta de dois indicadores de qualidade do ar, X e Y, é expressa por ƒ(x, y) = αxy, em que 0 ≤ x ≤ 1, 0 ≤ y ≤ 1 e α > 0. Para outros valores de x e de y, ƒ(x, y) = 0. Com base nessas informações, julgue o próximo item.
É correto afirmar que α é um parâmetro da distribuição que
pode assumir qualquer valor real positivo, e, a partir de uma
amostra aleatória simples, esse parâmetro pode ser estimado
pelo método dos momentos.
Deseja-se estimar o total de carboidratos existentes em um lote de 500.000 g de macarrão integral. Para esse fim, foi retirada uma amostra aleatória simples constituída por 5 pequenas porções desse lote, conforme a tabela seguinte, que mostra a quantidade x amostrada, em gramas, e a quantidade de carboidratos encontrada, y, em gramas.

Com base nas informações e na tabela apresentadas, julgue o item a seguir.
Considerando-se o modelo de regressão linear na forma
y = ax + ε, em que ε denota o erro aleatório com média nula e
variância V, e a representa o coeficiente angular, a estimativa
de mínimos quadrados ordinários do coeficiente a é igual ou
superior a 0,5.
Deseja-se estimar o total de carboidratos existentes em um lote de 500.000 g de macarrão integral. Para esse fim, foi retirada uma amostra aleatória simples constituída por 5 pequenas porções desse lote, conforme a tabela seguinte, que mostra a quantidade x amostrada, em gramas, e a quantidade de carboidratos encontrada, y, em gramas.
Com base nas informações e na tabela apresentadas, julgue o item a seguir.
Considerando o estimador de razão, estima-se que existem
250.000 g de carboidratos nesse lote de macarrão integral.
X1, X2, ..., X10 representa uma amostra aleatória simples retirada de uma distribuição normal com média µ e variância σ2 , ambas desconhecidas. Considerando que 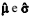 representam os respectivos estimadores de máxima verossimilhança desses parâmetros populacionais, julgue o item subsecutivo.
representam os respectivos estimadores de máxima verossimilhança desses parâmetros populacionais, julgue o item subsecutivo.
A soma X1+ X2 +...+ X10 é uma estatística suficiente para a estimação do parâmetro µ.
A partir da situação hipotética apresentada e considerando Φ(2) = 0,977, em que Φ(z) representa a função de distribuição acumulada de uma distribuição normal padrão e z é um desvio padronizado, julgue o item que se segue, com relação ao teste de hipóteses H0 = µ ≥ 60 minutos, contra HA = µ < 60 minutos, em que H0 e HA denotam, respectivamente, as hipóteses nula e alternativa.
O P-valor (ou nível descritivo do teste) foi superior a 2,3%.
A partir da situação hipotética apresentada e considerando Φ(2) = 0,977, em que Φ(z) representa a função de distribuição acumulada de uma distribuição normal padrão e z é um desvio padronizado, julgue o item que se segue, com relação ao teste de hipóteses H0 = µ ≥ 60 minutos, contra HA = µ < 60 minutos, em que H0 e HA denotam, respectivamente, as hipóteses nula e alternativa.
Nesse teste de hipóteses, comete-se o erro do tipo II caso a
hipótese H0 seja rejeitada, quando, na verdade, H0 não deveria
ser rejeitada.
Em pesquisa realizada para se estimar o salário médio dos empregados de uma empresa, selecionou-se, aleatoriamente, uma amostra de nove empregados entre todos os empregados da empresa. Os dados de tempo de serviço, em anos, e salário, em quantidade de salários mínimos, dos indivíduos dessa amostra estão dispostos na tabela abaixo.

A partir dos dados da tabela, julgue o item seguinte.
Excluindo-se da amostra um empregado qualquer, nem o menor
salário nem a moda amostral sofreriam alterações com relação aos
valores observados na amostra completa.
Uma empresa encomenda uma pesquisa de mercado que utilize o método de amostragem aleatória simples.
Esse é um caso de amostra probabilística em que cada entrevistado
Com o objetivo de avaliar a eficácia de um discurso político na opinião dos eleitores, foi realizado um grupo focal que avaliou as reações de uma amostra de eleitores sobre o discurso. A ideia é medir a significância das mudanças de opinião nos ouvintes, resultantes do discurso. A Tabela abaixo apresenta os movimentos dos pareceres dos 30 ouvintes que participaram do estudo.
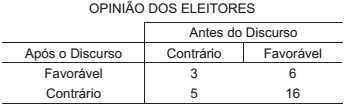
A hipótese nula de indiferença dos eleitores na amostra em relação ao discurso deverá ser refutada para valores da estatística acima de 3,8, a 5% de significância.
Assim sendo, com base nos resultados da amostra, conclui-se
que o discurso
Um modelo de regressão linear simples, Y = β0 + β1 X + ε, foi aplicado para explicar o consumo de um certo bem em função da taxa de desemprego. Uma amostra aleatória de tamanho 40 foi selecionada e forneceu a informação de que, para cada elevação de 1% na taxa de desemprego, a demanda diminui em 1.000 unidades. A tabela de ANOVA apresenta informações para testar a significância do modelo, fornecendo a estatística do teste F = 400 com Fsig = 9,0 × 10-22.
O valor da estatística t de Student para o teste da significância de β1 é