Questões de Concurso Sobre estatística
Foram encontradas 11.338 questões
Sobre o modelo de regressão com variável dependente binária, considere as afirmativas a seguir.
I – O modelo não pode incluir variáveis independentes contínuas.
II – A função probito é uma das possíveis funções de ligação entre a variável resposta e as variáveis independentes.
III – A estatística deviance é calculada como o logaritmo da razão de chances.
É correto o que se afirma em
O modelo de regressão linear Y = β0 + β1 X1 + ε foi aplicado a um conjunto de dados, sendo ε o ruído branco.
Considere a tabela ANOVA, incompleta, resultante a seguir.
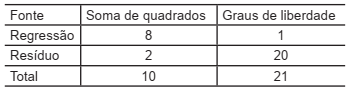
Se uma nova variável X2
for incorporada ao modelo, o
coeficiente de determinação, R2
, será
A investigação do número diário de navios que partem de um porto concluiu que a série segue o processo AR(1)
Xt = μ + ϕXt−1 + ... + εt
onde εt é ruído branco.
A função de autocorrelação amostral dos dados analisados apresenta os seguintes valores:
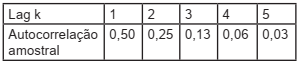
Com base nas informações acima, a estimativa do parâmetro
φ obtida pelo método dos momentos é
Considere o modelo de regressão linear simples: Y = a + bX + u, em que Y é a variável dependente, X é o regressor, u é o termo aleatório e a e b são parâmetros.
Se Cov(X,u)≠0, então o estimador de b por mínimos quadrados ordinários será
Seja X e Y, duas variáveis aleatórias.
Uma forma de mensurar a covariância entre ambas é por meio da seguinte expressão:
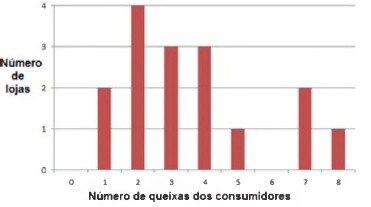
Figura 1: Gráfico do número de queixas por loja.
Baseando-se em sua análise, assinale a alternativa correta:
Considere as seguintes descrições de distribuições de probabilidade de variáveis aleatórias:
◾Distribuição 1: expressa a probabilidade de que uma dada quantidade de eventos ocorra em um dado intervalo de tempo, se conhecemos a taxa média de ocorrência desses eventos nesse intervalo de tempo, e se a ocorrência de um evento é independente do momento da ocorrência do evento anterior.
◾Distribuição 2: expressa o número de sucessos numa sequência de n experimentos feitos de forma que: cada experimento tem exclusivamente como resultado duas possibilidades, sucesso ou fracasso; cada experimento é independente dos demais; e a probabilidade de sucesso em cada evento é sempre a mesma.
As distribuição descritas acima são, respectivamente:
Uma pizzaria tem no seu cardápio 3 grupos de sabores de pizzas:
◾ Pizzas Tradicionais
◾ Pizzas Especiais
◾ Pizzas Gourmet
Ao todo, há 15 pizzas Tradicionais, cada uma no valor de R$ 35,00, 10 pizzas Especiais, cada uma no valor de R$ 40,00, e 5 pizzas Gourmet, cada uma no valor de R$ 46,00.
Levando em conta todas as pizzas vendidas por essa pizzaria, podemos afirmar que a média, a mediana e a moda dos valores são, respectivamente:
Em duas pesquisas independentes sobre educação em um município foram selecionados aleatoriamente alunos de quinto ano do ensino fundamental de todas escolas do município para realizarem provas de sondagem (as provas são idênticas nas duas pesquisas). A média aritmética simples das notas obtidas pelos alunos que realizaram a prova de uma pesquisa foi 6,6, enquanto que a média aritmética simples das notas obtidas pelos alunos que realizaram a prova da outra pesquisa foi 5,4.
O seguinte teste de hipótese foi desenhado:
◾ Hipótese H0 : A média da população é igual a 6,6.
◾ Hipótese H1 : A média da população é igual a 5,4.
Serão aleatoriamente selecionadas 10 provas e calculada a média X dessas 10 provas.
Se X > 6 será aceita a hipótese H0 , caso contrário, será rejeitada a hipótese H0 .
Foi calculado que a probabilidade de se cometer o ERRO DE TIPO I é de 5,3%, e que a probabilidade de se cometer o ERRO DE TIPO II é de 4,3%.
Ao realizar o teste de hipóteses acima, se encontrou X = 6,2.
Analise a frase abaixo a respeito do experimento e do teste de hipóteses:
Devemos …………………… que a média da população é 6,6, mas temos ……… de probabilidade de estarmos …………………… .
Assinale a alternativa que completa corretamente as lacunas do texto.
Uma agência de publicidade quer estimar o grau de preferência entre dois produtos (A e B) concorrentes pelos usuários do cartão-fidelidade de uma certa rede de supermercados. Para isso, realizará uma sondagem junto a uma população de amostra dos usuários do cartão.
Os usuários selecionados terão de escolher uma das seguintes opções:
1. Não tenho preferência entre (ou não uso) esses produtos
2. Prefiro o produto A
3. Prefiro o produto B
Para selecionar a amostra, a agência deve decidir entre um dos seguintes métodos de amostragem:
◾Método 1: selecionar aleatoriamente, no cadastro de usuários do cartão, 100 usuários de cartão de crédito e lhes enviar uma enquete.
◾Método 2: com base no cadastro, organizar os clientes da rede de supermercados em grupos de acordo a faixa etária e então selecionar 100 usuários do cartão-fidelidade aleatoriamente e de forma proporcional à quantidade de clientes em cada faixa etária considerada.
◾Método 3: convidar por meio de e-mail cada usuário do cartão para que participe da pesquisa de opinião, e utilizar como população de amostra os usuários que se disponibilizarem a responder o questionário.
Os métodos descritos acima são, respectivamente:
Com base nessas informações, julgue o item subsecutivo, relativo ao teste de comparação entre médias.
No caso da média populacional, o intervalo de confiança e o
intervalo de credibilidade (usando-se uma priori não
informativa) são numericamente iguais, mas com
interpretações diferentes.
Com base nessas informações, julgue o item subsecutivo, relativo ao teste de comparação entre médias.
Considere que a expectativa fosse de que o tempo médio de
análise dos processos cairia 25% após a informatização.
Nesse caso, se 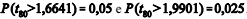 ,
infere-se que o objetivo foi alcançado.
,
infere-se que o objetivo foi alcançado.
Com base nessas informações, julgue o item subsecutivo, relativo ao teste de comparação entre médias.
Sabendo-se que as variâncias populacionais sejam iguais, é
correto afirmar que a estatística do teste é superior a 2.
Com base nessas informações, julgue o item subsecutivo, relativo ao teste de comparação entre médias.
Considere que se pretenda calcular o intervalo de confiança
clássico com 95% de confiança para a diferença dos tempos.
Nessa situação, se fossem feitos 100 intervalos com base em
amostras de mesmo tamanho, 95 desses conteriam o parâmetro,
diferentemente do intervalo bayesiano de credibilidade, o que
indica que a probabilidade de o parâmetro estar dentro do
intervalo é de 95%.
Com base nessas informações, julgue o item subsecutivo, relativo ao teste de comparação entre médias.
Para a verificação da efetividade da informatização do sistema,
a hipótese nula deve ser dada por H0: μD – μA = 0, em que μD
e μA são, respectivamente, a média logo após a informatização
e a média antes da informatização, o que significa que o
denominador da estatística do teste é dado, também, pela
diferença das variâncias.
Com base nessas informações, julgue o item subsecutivo, relativo ao teste de comparação entre médias.
Para calcular a potência do teste, é suficiente realizar 1- β, em que β é probabilidade de erro do tipo II e μ é o mesmo valor utilizado para calcular o teste com α (probabilidade de erro do tipo I)
Com base nessas informações, julgue o item subsecutivo, relativo ao teste de comparação entre médias.
O teste t apropriado à situação em tela é o teste para dados
pareados.

Considerando a tabela acima, que apresenta o registro das quantidades anuais de processos abertos contra autoridades públicas nas duas últimas décadas, julgue o item.
Ao se testar a hipótese nula de a média populacional ser igual
a 2 mediante a aplicação do teste t, verifica-se que a estatística
do teste apresenta valor positivo.
Considerando a tabela acima, que apresenta o registro das quantidades anuais de processos abertos contra autoridades públicas nas duas últimas décadas, julgue o item.
Utilizando-se o teste de aderência desses dados à distribuição
de Poisson com parâmetro igual a 1, a estatística quiquadrado
apresentará dois graus de liberdade.
Considerando a tabela acima, que apresenta o registro das quantidades anuais de processos abertos contra autoridades públicas nas duas últimas décadas, julgue o item.
Em qualquer teste qui-quadrado, a estatística do teste é
calculada utilizando-se a diferença entre valores observados e
valores esperados.