Questões de Concurso Sobre estatística
Foram encontradas 11.296 questões
Considerando uma distribuição condicional expressa na forma de função de densidade de probabilidade f(x|y) = ye-xy, em que e denota a constante de Euler, e x e y, valores reais positivos que representam, respectivamente, os pontos de suporte das variáveis aleatórias contínuas X e Y, julgue o item a seguir.
P(X > 1|Y = 2) = e –2.
Se Y seguir uma distribuição exponencial com média igual a 1, então, para x > 0, a função de densidade da variável aleatória X será f(x) = (x + 1)-2.
Acerca da Teoria da dualidade, assinale a afirmativa CORRETA:
10 ± 4 representa a estimativa intervalar de 95% de confiança para a média de uma população normal, tendo sido obtida a partir de uma amostra aleatória de tamanho n . Para a obtenção dessa estimativa, considerou-se que a variância populacional fosse conhecida. Em novo levantamento feito sobre essa mesma população, mas, dessa vez, tendo-se quadruplicado o tamanho da amostra (4n), foi obtida média amostral igual a 8.
Nesse caso, se 8 ± ε representar a nova estimativa intervalar de 95% de confiança para a média dessa população, é correto afirmar que ε deverá ser igual a
O conjunto de dados {0, 4, 3, 3, 0} é uma realização de uma amostra aleatória simples retirada de uma população binomial com parâmetros n e p, sendo n = 4 e p uma probabilidade desconhecida.
Com base nessas informações, é correto afirmar que a estimativa de máxima verossimilhança para a probabilidade de ocorrência do valor 2 na população em questão é igual a
Se N for uma variável aleatória que siga uma distribuição normal
com média igual a 10 e desvio padrão igual a 5 e se Z =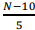 , então a probabilidade de ocorrência do evento “Z = 1,96” será
igual a
, então a probabilidade de ocorrência do evento “Z = 1,96” será
igual a
Supondo-se que a variável aleatória X possa assumir valores 0, 1,
2 ou 3 conforme a função de distribuição de probabilidade P(X = h) = 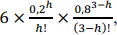 na qual h ∈ {0, 1, 2, 3}, é correto
afirmar que o valor esperado de X seja igual a
na qual h ∈ {0, 1, 2, 3}, é correto
afirmar que o valor esperado de X seja igual a
Um modelo de regressão linear múltipla com dez coeficientes foi ajustado pelo método de mínimos quadrados ordinários, tendo produzido um coeficiente de determinação (R2) igual a 80%.
Nessa hipótese, caso o tamanho da amostra utilizado para esse ajuste tenha sido igual a 46, então o valor correspondente do coeficiente conhecido como “R2 ajustado” deve ter sido igual a
Em um modelo de regressão linear simples na forma y = ax + b + ∈, x representa a variável regressora, y denota a variável resposta e ∈ é um erro aleatório com média zero e variância 100.
Nessa hipótese, considerando-se que â denote o estimador de mínimos quadrados ordinários do coeficiente produzido por uma amostra aleatória de tamanho igual a 101 e que o desvio padrão amostral da variável regressora seja igual a 2, é correto afirmar que o desvio padrão de â será igual a
Um analista pretende ajustar um modelo de regressão linear simples com um intercepto e um coeficiente angular β, utilizando uma amostra de tamanho igual a 402.
Nessa situação, se a razão t correspondente à estimativa de β a ser obtida pelo método de mínimos quadrados ordinários for igual a 20, então o coeficiente de explicação (ou determinação) R2 proporcionado pelo modelo em tela será igual a
A respeito do modelo de séries temporais St = ɛt + ɛt-12 + ɛt-24 + ɛt-36 + ... = 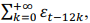 no qual t ∈ ℤ representa um índice temporal e εt denota um erro
aleatório no instante t, que segue uma distribuição normal com
média zero e desvio padrão 5, assinale a opção correta.
no qual t ∈ ℤ representa um índice temporal e εt denota um erro
aleatório no instante t, que segue uma distribuição normal com
média zero e desvio padrão 5, assinale a opção correta.
Se {yt} for uma série temporal fracamente estacionária descrita pelo modelo na forma yt = 3 + 0,7yt−1 + εt , no qual εt é um ruído branco com média nula e t ∈ ℤ, então o valor esperado da variável yt será igual a
Nos seguintes modelos de séries temporais, Xt representa uma observação e wt denota um ruído branco no instante t ∈ ℤ.
I Xt = Xt-1 − 0,25Xt-2 + wt − 0,5wt-1
II Xt = wt − 0,5wt-1
III Xt = 0,8Xt-1 − 0,5wt
IV Xt = 0,09Xt-2 + wt − 0,3wt-1
Considerando os modelos de séries temporais apresentados,
assinale a opção em que é corretamente indicada a quantidade de
modelos cuja função de autocorrelação apresenta a forma de um
processo autorregressivo de primeira ordem.
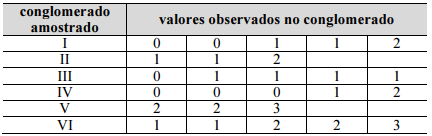
Considerando que a tabela precedente apresenta resultados brutos
de uma amostragem aleatória por conglomerados, é correto
afirmar que o tamanho amostral (n) desse levantamento foi
igual a
Um estudo por amostragem aleatória estratificada foi realizado para estimar a fração (p) de empresas com alguma dívida fiscal. A população, constituída por 500 empresas, foi dividida em três estratos, conforme a tabela a seguir. Enquanto p representa uma fração global, denota-se como Pk a fração de empresas do estrato k com alguma dívida fiscal. Assim, a tabela também mostra o tamanho da amostra em cada estrato, bem como o erro padrão do estimador de Pk.
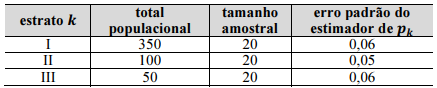
Com base nessas informações, se 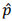 representar o estimador da
fração global de empresas com alguma dívida fiscal, a estimativa
da variância de será
representar o estimador da
fração global de empresas com alguma dívida fiscal, a estimativa
da variância de será
Um levantamento por amostragem aleatória simples (sem
reposição) será efetuado sobre uma população constituída por N = 225 empresas. O objetivo dessa amostragem é estimar o
parâmetro 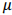 , que representa o preço médio (populacional) de
determinado produto comercializado por essas empresas. Se
, que representa o preço médio (populacional) de
determinado produto comercializado por essas empresas. Se 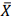 denota a média amostral, a margem de erro (∈) com 95% de
confiança é
denota a média amostral, a margem de erro (∈) com 95% de
confiança é 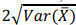 . O desvio padrão populacional dos
preços é igual a R$ 400.
. O desvio padrão populacional dos
preços é igual a R$ 400.
Nessa situação hipotética, para que a margem de erro seja igual a R$ 200, o tamanho da amostra para esse levantamento deverá ser igual a
Nessa situação hipotética, se as contagens X e Y f orem independentes, o desvio padrão da diferença Y - X será igual a