Questões de Concurso
Foram encontradas 10.182 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Q1933593
Estatística
Um problema comum no processamento de texto é o tratamento
de termos compostos por mais de um token, tais como
“Ministério Público”, tal que represente uma unidade linguística
distinta, em particular na construção de modelos de linguagem.
Considerando o problema acima descrito, a alternativa que apresenta uma técnica usada para sua resolução é:
Considerando o problema acima descrito, a alternativa que apresenta uma técnica usada para sua resolução é:
Q1933592
Estatística
O método Latent Dirichlet Allocation (LDA) é popularmente
utilizado para a construção de modelos de tópicos devido a sua
flexibilidade e robustez, particularmente em grandes quantidades
de texto. Ao mencionar a escolha do LDA em um projeto, um
analista foi questionado sobre que aspectos caracterizam a
flexibilidade do modelo, especialmente em comparação a um
modelo pLSA.
O analista respondeu corretamente:
O analista respondeu corretamente:
Q1933591
Estatística
Um modelo semântico vetorial foi criado com a seguinte
definição:
v(w)i = tf(w, di) ∙ idf(w, D)
onde v é o vetor correspondente à palavra w, di é o i-ésimo documento da coleção D de artigos da Wikipédia, ordenados alfabeticamente por título, e tf e idf são, respectivamente, as funções de frequência de termo e inverso da frequência em documentos.
A alternativa que classifica corretamente o modelo acima descrito e apresenta a razão correta para a classificação é:
v(w)i = tf(w, di) ∙ idf(w, D)
onde v é o vetor correspondente à palavra w, di é o i-ésimo documento da coleção D de artigos da Wikipédia, ordenados alfabeticamente por título, e tf e idf são, respectivamente, as funções de frequência de termo e inverso da frequência em documentos.
A alternativa que classifica corretamente o modelo acima descrito e apresenta a razão correta para a classificação é:
Q1933590
Estatística
A atividade de classificação de documentos envolve um grande
número de tarefas de processamento de linguagem natural, o
que pode levar a dúvidas quanto a sua aplicação.
A alternativa que contém apenas tarefas que sejam exemplos de classificação de documentos é:
A alternativa que contém apenas tarefas que sejam exemplos de classificação de documentos é:
Q1933589
Estatística
Para realizar o agrupamento de um conjunto de 4 observações
(A, B, C e D) foi decidido usar o método de agrupamento
hierárquico aglomerativo com ligação simples (single-linkage).
A matriz de distância inicial entre os elementos é apresentada a seguir.
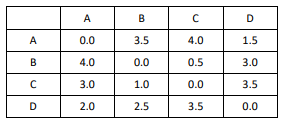
Considerando essas informações, a matriz de distância obtida após o primeiro passo do agrupamento é:
A matriz de distância inicial entre os elementos é apresentada a seguir.
Considerando essas informações, a matriz de distância obtida após o primeiro passo do agrupamento é:
Q1933588
Estatística
A aplicação do algoritmo AdaBoost, utilizando classificadores
SVM, permitiu a obtenção de um modelo classificador de sinais
sonoros com excelente precisão. Entretanto, esse modelo possui
requisitos computacionais além da capacidade da plataforma
onde se deseja aplicá-lo.
Considerando o problema acima descrito, a técnica a ser utilizada para contornar o problema é:
Considerando o problema acima descrito, a técnica a ser utilizada para contornar o problema é:
Q1933586
Estatística
Uma biblioteca está classificando os seus frequentadores em
grupos literários para facilitar a aquisição e a organização dos
livros. Isso foi feito aplicando o algoritmo KNN ao banco de dados
de usuários da biblioteca, incluindo alguns dos campos de
informação como atributos, tais como idade e nível de formação
acadêmica. Em um experimento, uma segunda classificação foi
feita usando um conjunto maior de atributos, incluindo ambos de
maior ou menor relevância percebida com relação aos grupos
definidos.
A segunda classificação tende a ser:
A segunda classificação tende a ser:
Q1933585
Estatística
Em um trabalho de pesquisa, as idades das pessoas são: 23, 27,
32, 33, 34, 35, 36, 38, 42, 56 e 58. Deseja-se construir um boxplot
similar ao gráfico a seguir.
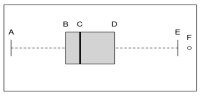
No boxplot acima, os valores das estatísticas nas posições indicadas pelas letras A, B, C, D, E e F são:
No boxplot acima, os valores das estatísticas nas posições indicadas pelas letras A, B, C, D, E e F são:
Q1933584
Estatística
Uma prefeitura recebeu uma denúncia de que o número de
autuações feitas pela equipe de fiscalização variava conforme o
dia da semana. Para verificar a procedência da denúncia, as
autuações foram agregadas por dia de semana, como mostra a
tabela a seguir.
Segundas 6 Terças 12 Quartas 9 Quintas 8 Sextas 15 Sábados 13 Domingos 7
Realizando um teste estatístico adequado para verificar se essas autuações ocorrem com a mesma frequência, teremos:
Segundas 6 Terças 12 Quartas 9 Quintas 8 Sextas 15 Sábados 13 Domingos 7
Realizando um teste estatístico adequado para verificar se essas autuações ocorrem com a mesma frequência, teremos:
Q1933583
Estatística
Uma empresa recebeu um lote muito grande, milhões de peças
de refugo, e deseja saber quantas peças deverá examinar para
estimar a proporção de itens defeituosos, de modo que o erro de
estimação seja no máximo 2%. Será empregada uma seleção
aleatória de itens onde cada um será classificado como
defeituoso ou não defeituoso. Deseja-se extrair uma amostra
aleatória de tamanho n.
Tendo como padrão um grau de confiança de 95%, o tamanho da amostra necessário para garantir o processo é:
Tendo como padrão um grau de confiança de 95%, o tamanho da amostra necessário para garantir o processo é:
Q1933582
Estatística
Em um processo de descontaminação é importante manter um
controle da variabilidade da contaminação residual que persiste
após o processo. Sabe-se que a mensuração do resíduo tem
distribuição normal, e que a partir de uma amostra aleatória, de
21 unidades, foi calculada a variância S2 = 54,25. Para
estabelecer uma medida máxima de referência, decidiu-se utilizar
o intervalo de confiança superior para o desvio padrão.
O valor desse limite a 95% de confiança é:
O valor desse limite a 95% de confiança é:
Q1933579
Estatística
Na avaliação de um modelo para detecção de fraude, foi utilizado
um conjunto de dados conhecido que resultou na matriz de
confusão abaixo.

É correto afirmar que o modelo apresenta:
É correto afirmar que o modelo apresenta:
Q1933578
Estatística
Uma sociedade empresária precisa decidir sobre o uso de 3
algoritmos distintos em uma tarefa específica. Então, fez um
experimento onde aplicou cada um dos algoritmos de forma
aleatória em um conjunto de tarefas similares, medindo sua
performance. Os resultados estão na tabela a seguir:
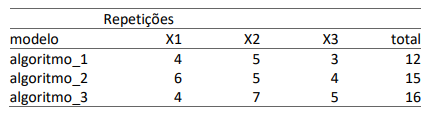
Se a performance é representada por Y e sabendo-se que
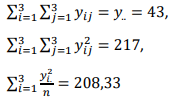
e os demais pressupostos inferenciais são atendidos, deseja-se saber se há evidências estatísticas que ao menos um algoritmo tenha performance diferente dos demais.
Considerando o ponto crítico da distribuição F(2,6) = 5,14, ao nível de significância a = 0,05, conclui-se que:
Se a performance é representada por Y e sabendo-se que
e os demais pressupostos inferenciais são atendidos, deseja-se saber se há evidências estatísticas que ao menos um algoritmo tenha performance diferente dos demais.
Considerando o ponto crítico da distribuição F(2,6) = 5,14, ao nível de significância a = 0,05, conclui-se que:
Q1933577
Estatística
Seja x uma amostra aleatória de tamanho 12. Foram então
geradas 10 amostras aleatórias com reposição de tamanho 12 de x e para cada uma delas foi calculada a mediana gerando os
seguintes valores: 3, 4, 4, 4 ,4, 5, 5 ,6 ,7 e 8.
A estimativa do erro padrão da mediana amostral é, aproximadamente:
A estimativa do erro padrão da mediana amostral é, aproximadamente:
Q1933576
Estatística
Considere um processo onde é observada uma variável aleatória X que tem distribuição Normal com média 4 e desvio padrão 2.
Após uma modificação no processo, os valores se alteraram e a
nova variável é Y = 2X + 4.
É correto afirmar que Y tem distribuição Normal com:
É correto afirmar que Y tem distribuição Normal com:
Q1933575
Estatística
O tempo, em horas diárias, que homens com idades entre os 40 e
50 anos acessam redes sociais segue uma distribuição Normal
com média 2,5 e desvio padrão 1,5. Para o mesmo grupo etário
de mulheres, esse tempo segue também uma distribuição Normal
com média 3 e desvio padrão 1. Serão retiradas duas amostras
casuais e independentes, uma de homens e outra de mulheres.
O tamanho mínimo da amostra da população das mulheres que se pretende com probabilidade pelo menos 0,95 e cuja diferença em valor absoluto entre a média amostral e a média populacional não exceda 0,1 é, aproximadamente:
O tamanho mínimo da amostra da população das mulheres que se pretende com probabilidade pelo menos 0,95 e cuja diferença em valor absoluto entre a média amostral e a média populacional não exceda 0,1 é, aproximadamente:
Q1933574
Estatística
É possível que o comportamento das bolsas de valores em
determinado mês prediga o seu comportamento o ano inteiro.
Considere que a variável explicativa X seja a variação percentual
do índice da bolsa em janeiro e que a variável de resposta Y seja a
variação desse índice para o ano inteiro. O cálculo feito com
dados do período de 5 anos teve como resultados:
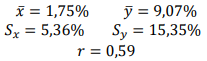
O percentual de variação observado nas alterações anuais do índice que é explicado pela relação linear com a alteração de janeiro é:
O percentual de variação observado nas alterações anuais do índice que é explicado pela relação linear com a alteração de janeiro é:
Q1933573
Estatística
Uma organização trabalhista deseja estudar as opiniões dos
professores universitários em relação às negociações coletivas da
categoria. Essa opiniões parecem ser diferentes de acordo com o
tipo de instituição em que esses profissionais trabalham.
Considere que as faculdades e universidades são classificadas da
seguinte forma:
• Grupo 1: Oferecem doutorado e formam um mínimo de 15 doutores por ano.
• Grupo 2: Oferecem graus acima do bacharelado mas não oferecem doutorado.
• Grupo 3: Não oferecem nenhum grau acima do bacharelado. Considere que há uma lista de todos os professores das universidades, mas, para facilitar o estudo, foi pensado em coletar uma amostra probabilística representativa dessa população.
O tipo de amostra mais indicada nesse caso seria:
• Grupo 1: Oferecem doutorado e formam um mínimo de 15 doutores por ano.
• Grupo 2: Oferecem graus acima do bacharelado mas não oferecem doutorado.
• Grupo 3: Não oferecem nenhum grau acima do bacharelado. Considere que há uma lista de todos os professores das universidades, mas, para facilitar o estudo, foi pensado em coletar uma amostra probabilística representativa dessa população.
O tipo de amostra mais indicada nesse caso seria:
Q1933572
Estatística
As variáveis aleatórias X e Y são tais que Var(X) = 1, Var(Y) =
4 e Cor(X, Y) = −1.
O valor de Var(Y − 2X) é:
O valor de Var(Y − 2X) é:
Q1933571
Estatística
Há evidências de que uma alta pressão sanguínea esteja
associada a um aumento de óbitos por problemas
cardiovasculares. Em um estudo foram examinados 3.000
homens com alta pressão sanguínea e 2.400 homens com baixa
pressão. Durante o período do estudo, 12 homens do grupo de
baixa pressão e 30 do grupo de alta pressão faleceram por
problemas cardiovasculares.
A chance de morrer de problemas cardiovasculares no grupo de alta pressão é dada, aproximadamente, por:
A chance de morrer de problemas cardiovasculares no grupo de alta pressão é dada, aproximadamente, por: